
Contents
- 00How to Use This Field Guide
- 01AI System Inventory
- 02Architecture and Trust Boundaries
- 03Threat Modeling
- 04Prompt Injection
- 05RAG Authorization
- 06Agentic Permissions
- 07Data Exposure and Privacy
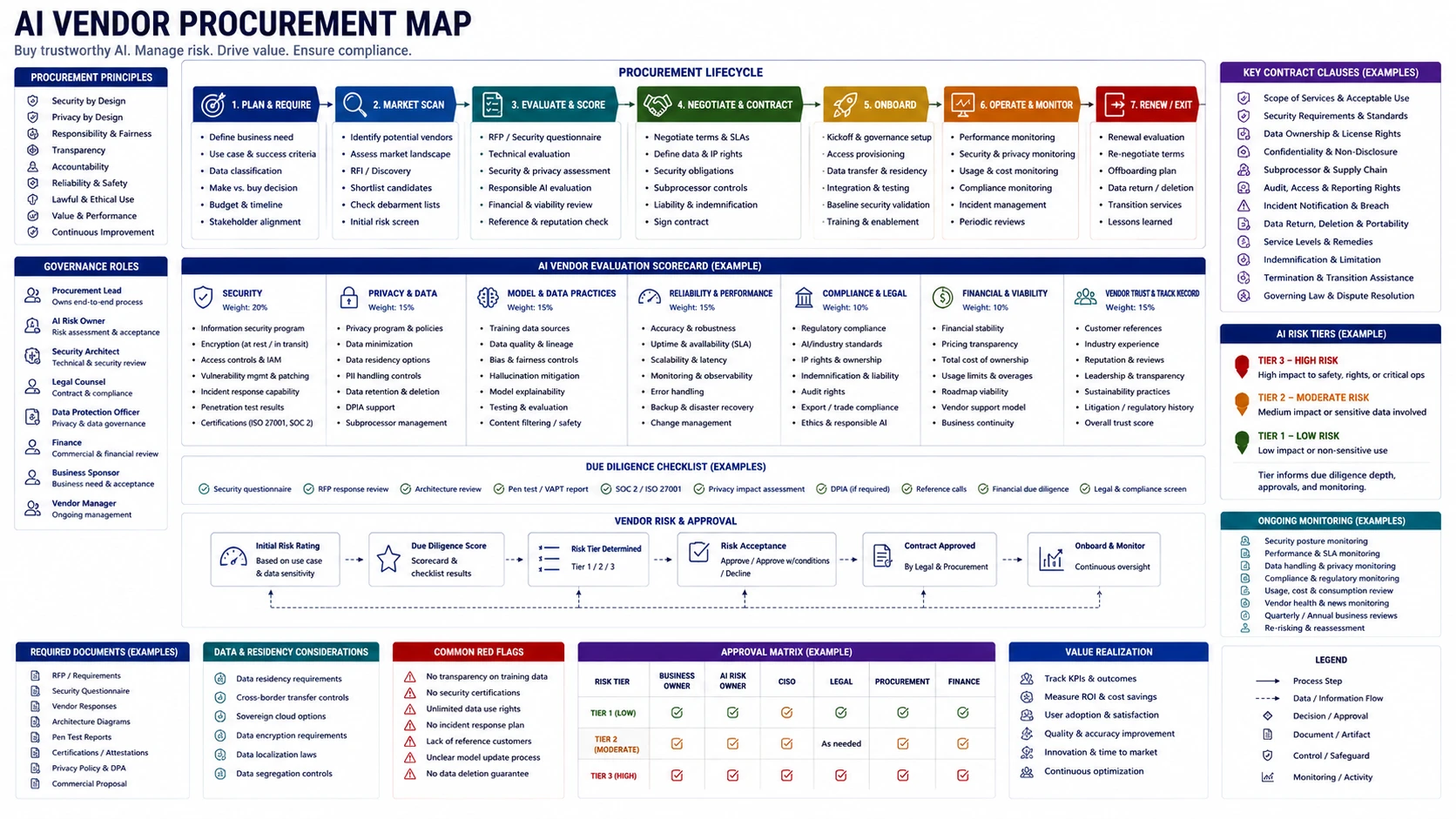
- 08Model and Provider Risk
- 09AI Supply Chain
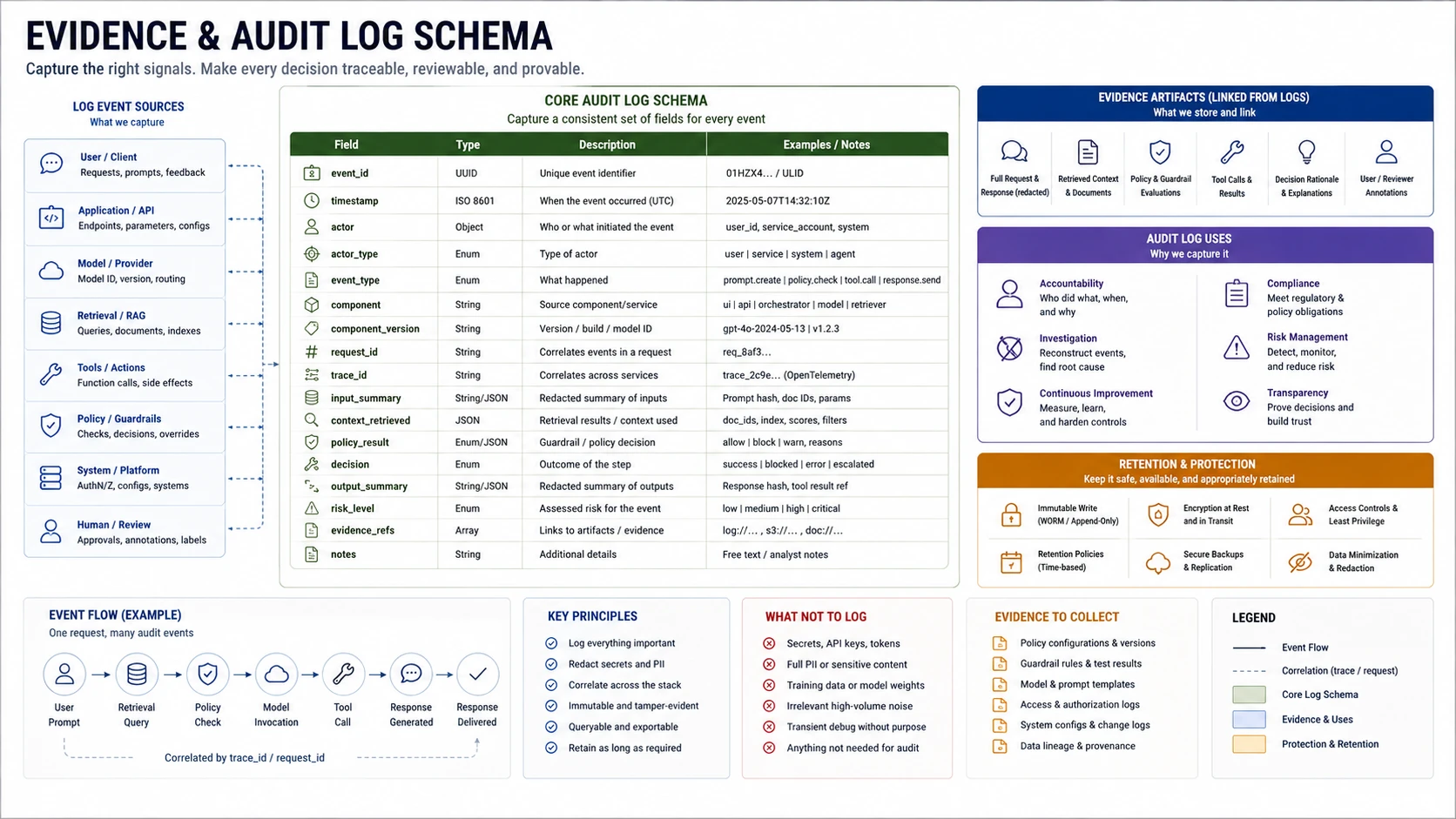
- 10Logging and Telemetry
- 11Detection Engineering
- 12Incident Response
- 13Evaluation and Regression Testing
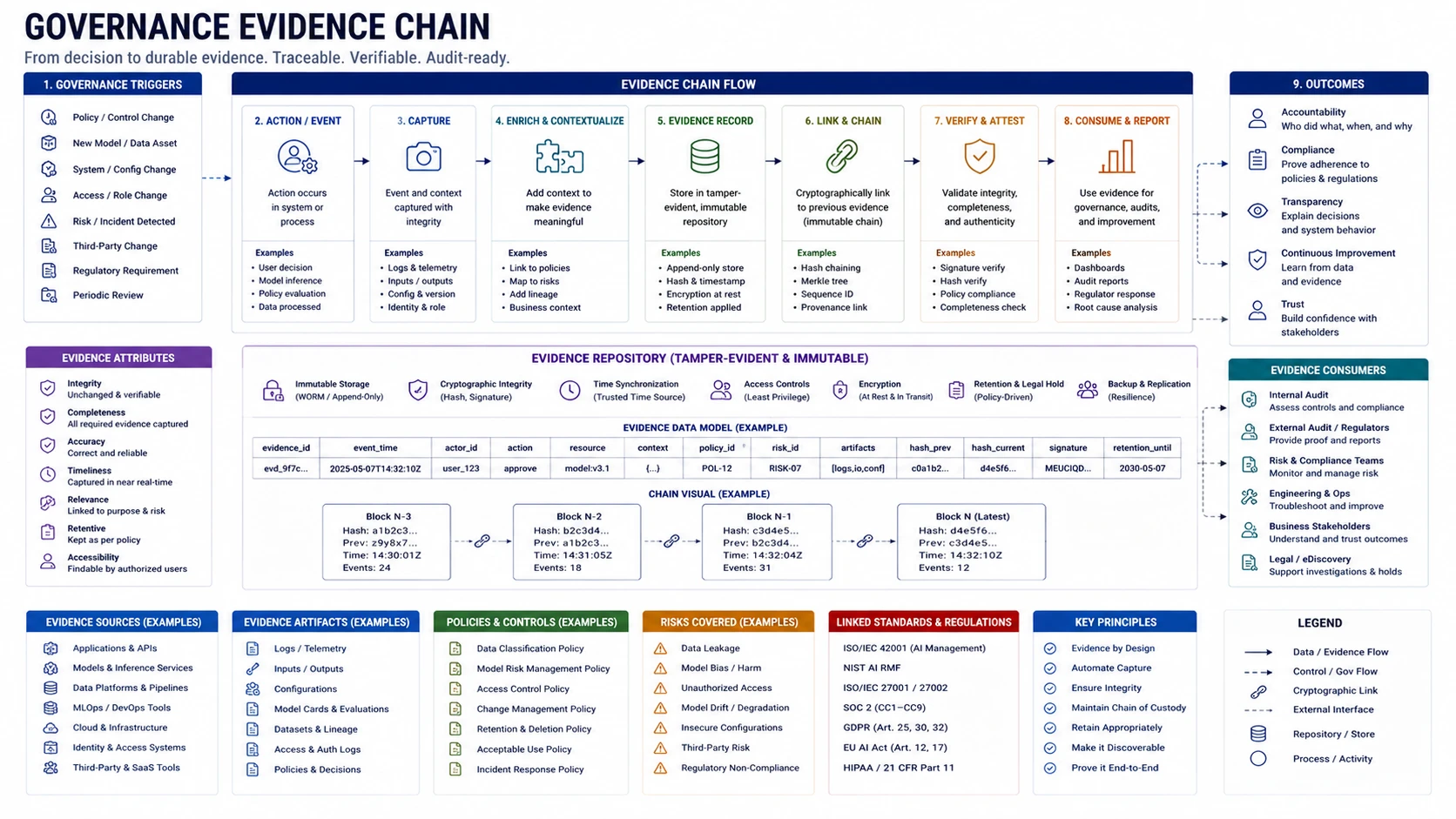
- 14Governance Evidence and Customer Trust
AI SECURITY ENGINEERING FIELD GUIDE · 00
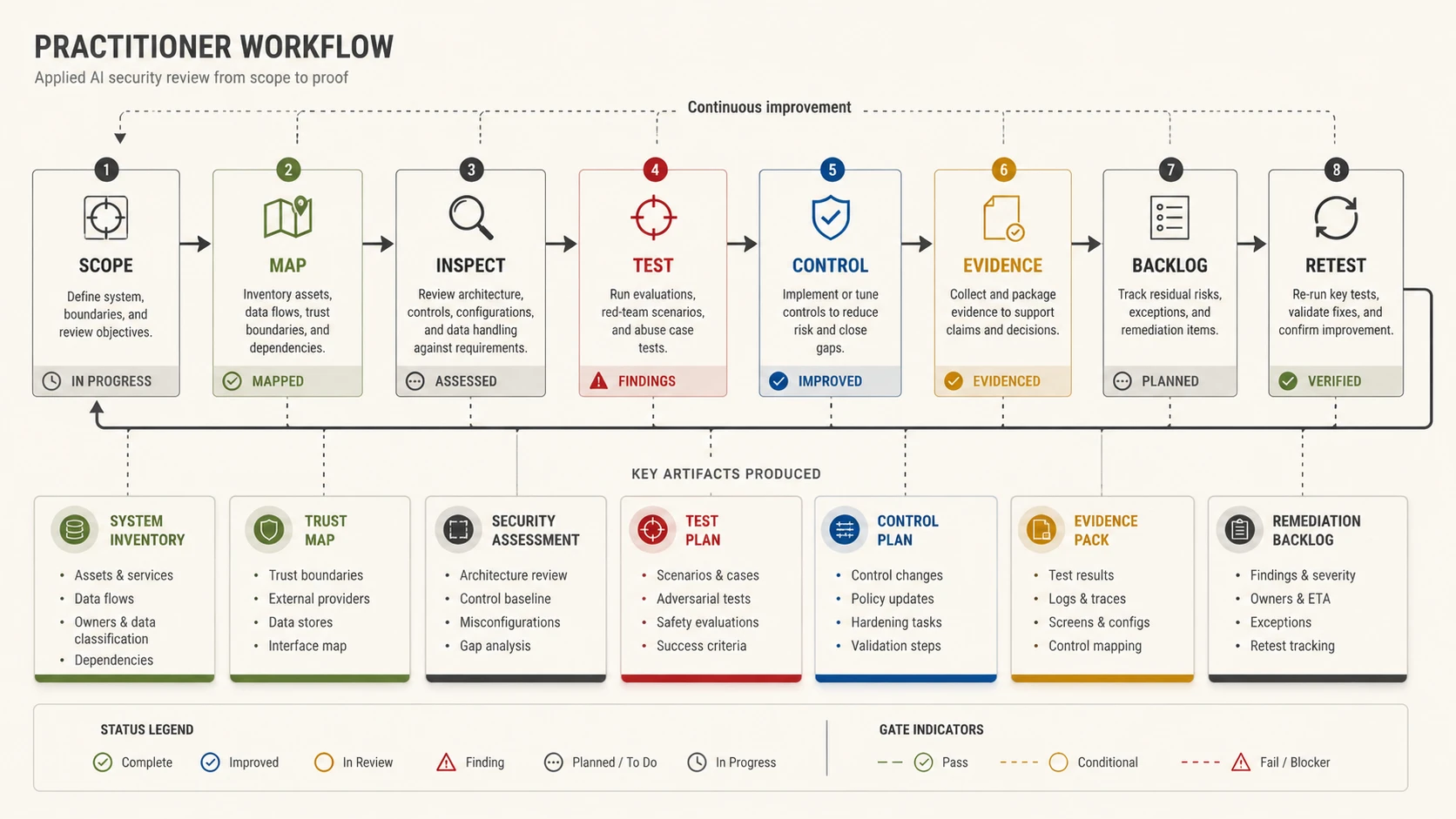
How to Use This Field Guide
Use
Run assessments, prepare architecture review questions, structure evidence requests, and convert findings into remediation work.
Output
Inventories, trust maps, test plans, evidence packs, permission matrices, and buyer-ready summaries.
A M.A.D.E. operational reference across 14 AI security engineering domains.
M.A.D.E. is the operating method: Map the system, Attack the abuse path, Defend the control plane, Evidence the result. Every domain in this guide applies that method. If the team cannot move through all four phases, it does not have a working AI security review yet.
The AI Security Engineering Field Guide is the operational companion to the AI Security Engineering Handbook.
Use the Handbook to learn each domain — system mechanics, domain concepts, the competency model, and the vocabulary behind controls.
Use the Field Guide to conduct reviews, test controls, make operational decisions, and retain evidence during live work.
How to use this Field Guide
Open the relevant domain. Scope the decision. Complete MAP. Challenge assumptions under ATTACK. Verify DEFEND controls. Collect EVIDENCE. Review stop-ship and escalation conditions. Record owner, decision, and next action.
Resource crosswalk
| Resource | Primary purpose |
|---|---|
| Handbook | Learn system mechanics and domain concepts |
| Field Guide | Execute reviews and operational decisions |
| Training | Practice implementation |
| Certification | Demonstrate competence |
| M.A.D.E. | Apply a repeatable workflow inside every domain |
Intended audience
Product-security practitioners, application-security engineers, security architects, AI engineers, red teamers, incident responders, cloud and platform engineers, and technical governance and assurance teams.
How to use the guide
- 1Open the relevant domain based on the system or decision under review.
- 2Scope the decision — what approval or risk determination is being made.
- 3Complete MAP — identify system scope, assets, identities, data, tools, providers, and existing evidence.
- 4Challenge assumptions under ATTACK — test abuse paths, negative cases, and failure conditions.
- 5Verify DEFEND controls — confirm required baseline controls exist and operate at the right enforcement point.
- 6Collect EVIDENCE — gather design, implementation, validation, runtime, and governance proof.
- 7Review stop-ship conditions and escalation triggers.
- 8Record owner, decision, and next action.
Use the right publication for the job
Open the Field Guide when a system needs inspection, testing, evidence, or an operational decision. Open the Handbook when the reader needs the conceptual model behind a domain.
Domain Spine
- 1AI System Inventory
- 2Architecture and Trust Boundaries
- 3Threat Modeling
- 4Prompt Injection
- 5RAG Authorization
- 6Agentic Permissions
- 7Data Exposure and Privacy
- 8Model and Provider Risk
- 9AI Supply Chain
- 10Logging and Telemetry
- 11Detection Engineering
- 12Incident Response
- 13Evaluation and Regression Testing
- 14Governance Evidence and Customer Trust
Cross-cutting lenses
The following lenses appear across multiple domains. They are not independent domains — they are methods and concerns that apply wherever the relevant system property exists.
MLOps — Model registries, artifact promotion, versioning, eval gates, pipeline integrity, drift monitoring, and rollback appear in: AI Supply Chain, Model and Provider Risk, Logging and Telemetry, Evaluation and Regression Testing, and Incident Response.
Secure SDLC — Design review, change triggers, release gates, code review for AI-specific code, dependency control, regression tests, and evidence retention appear in: Architecture and Trust Boundaries, Threat Modeling, AI Supply Chain, Evaluation and Regression Testing, and Governance Evidence and Customer Trust.
Red Team — Adversarial inputs, abuse-path validation, and finding-to-regression conversion appear in: Threat Modeling, Prompt Injection, RAG Authorization, Agentic Permissions, Detection Engineering, and Evaluation and Regression Testing.
Procurement — Provider terms, contractual controls, data-use commitments, audit rights, change notification, and portability appear in: Model and Provider Risk, Data Exposure and Privacy, AI Supply Chain, and Governance Evidence and Customer Trust.
Practitioner checklist
Artifacts this guide helps produce
- AI system inventory.
- Request-path diagram with trust-boundary overlays.
- Threat model with abuse-path register.
- Prompt injection test results and regression suite.
- RAG boundary assessment and cross-tenant test results.
- Agent authority matrix and tool permission review.
- AI data-flow and derived-record map.
- Provider intake record and data processing terms review.
- AI artifact bill of materials and registry promotion records.
- Log schema specifications and trace reconstruction results.
- Detection hypothesis register and rule validation results.
- Incident response playbook and tabletop exercise records.
- Security test suite with release gate definitions.
- Control registry and claim-readiness register.
AI SECURITY ENGINEERING FIELD GUIDE · 01
AI System Inventory
Inspect
AI inventory, owners, data flows, risk tiers, evidence paths, and release gates.
Produce
System inventory, trust-boundary map, owner register, and evidence request list.
“You cannot review, test, or govern an AI system you have not inventoried.”
Inventory review
Produce one row per live AI feature: owner, model/provider, data class, tool authority, execution identity, risk tier, evidence location. That row is the starting point for every other domain.
Inventory is scoping work. Without it, threat models lack scope and governance claims cannot be traced to a system. Shadow AI, vendor-embedded copilots, and internal experiments are in scope if they read sensitive data, call a provider, or write to a business system.
Test: can the team show one row per live AI feature — owner, risk tier, evidence location — without manual reconstruction? If not, the system is not ready for architecture review, release gating, or incident scoping.
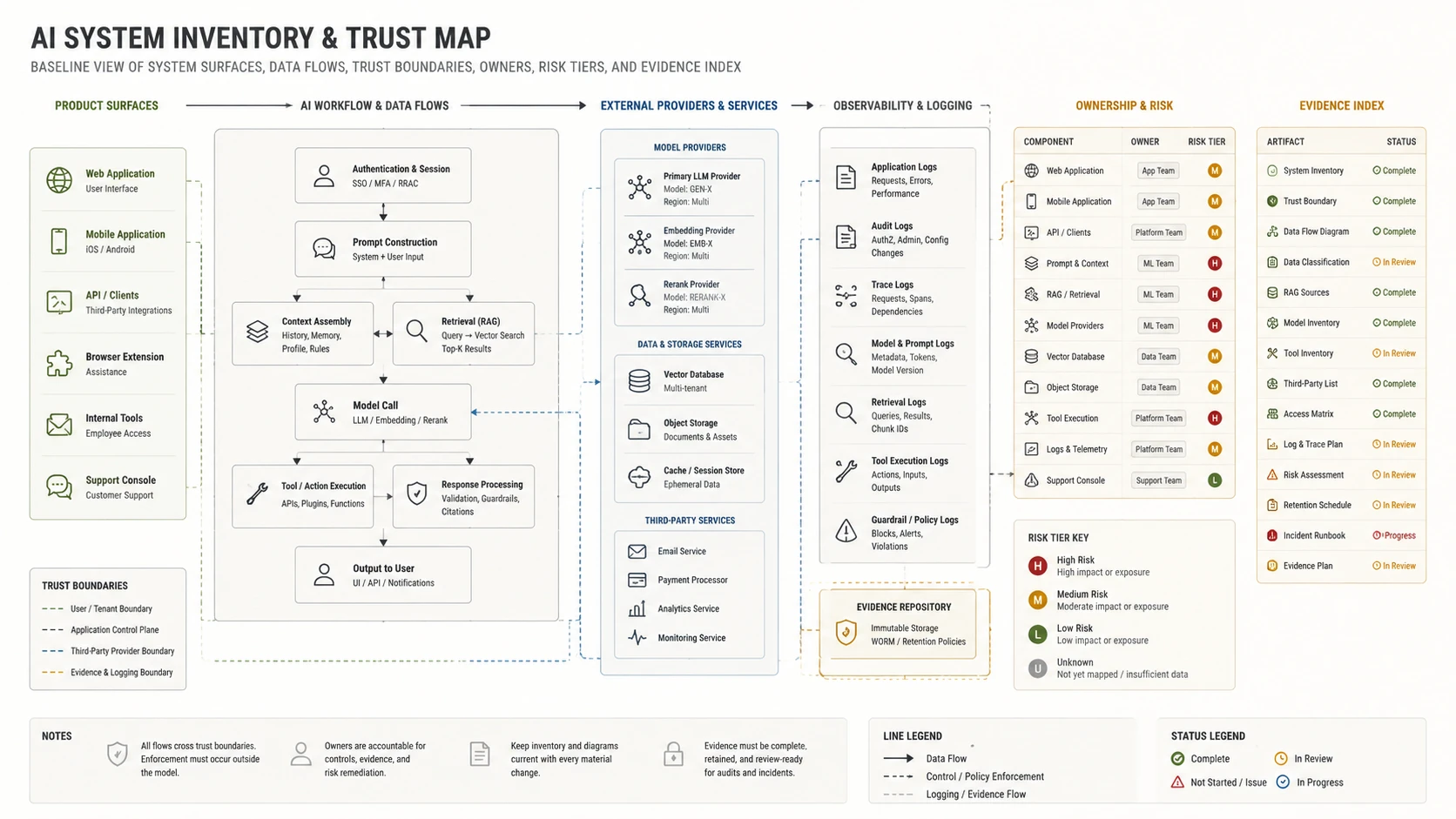
When to use: Before every other domain review. Required at architecture review, release gating, incident scoping, governance evidence, provider onboarding.
MAP
MAP
ATTACK
ATTACK
- Compare declared inventory against code search, vendor spend, API gateway logs, and telemetry for external LLM calls.
- Search Slack, source control, and billing for unofficial integrations and shared API keys.
- Verify every high-risk system has a named owner; block if none exists.
- Trace a system from production traffic back to its inventory record; confirm fields are current.
- Compare tool manifests in code against inventory; flag undeclared tools.
- Sample recent releases for systems that shipped without an inventory entry.
DEFEND
DEFEND — Required baseline
- Inventory record per system: owner, model/provider, data class, tool authority, identity, risk tier, approval status, evidence location.
- Intake gate: new features, providers, retrieval sources, and tools require an entry before deployment.
- Risk tiers based on data sensitivity, delegated authority, exposure, and reversibility — not revenue or excitement.
- Change triggers: model, provider, retrieval, or tool-scope change reopens the record for re-approval.
- Periodic reconciliation between inventory and production telemetry.
DEFEND — High-risk and advanced
- High-risk systems
- Dependency records linking the system to upstream sources and downstream consumers.
- Direct pointers from inventory to threat model, tests, and exceptions.
- Advanced maturity
- Automated discovery: detect provider calls in telemetry, alert on unregistered endpoints.
- Continuous reconciliation against live API traffic with drift alerting.
Stop-ship conditions
- No accountable owner for a production AI system.
- A production system is absent from the inventory.
- Model or provider is unknown or unapproved.
- Data classification is missing.
- No evidence location for a high-risk system.
Escalate when
EVIDENCE
EVIDENCE
- Design: inventory schema, risk-tier criteria.
- Implementation: inventory export, intake gate records, change-trigger log.
- Validation: reconciliation report, gap register.
- Runtime: telemetry confirming inventoried systems produce expected logs.
- Governance: exception register, periodic reconciliation records.
Minimum evidence package
Inventory export, owner register, risk-tier rationale, change-trigger list, gap register. Every high-risk system needs a named owner and reachable evidence location.
Field decision questions
- Can the team produce one row per live AI system without manual reconstruction?
- Which systems lack an owner, data class, or evidence location?
- What change would invalidate this record and require re-review?
- Which systems are in scope but absent from the inventory?
Outputs
- AI system inventory.
- Ownership and approver register.
- Risk-tier worksheet.
- Gap register.
Related domains
| Domain | When to consult |
|---|---|
| [Architecture and Trust Boundaries](/handbook/2026#chapter-02) | Trace a request path for every inventoried system. |
| [Threat Modeling](/handbook/2026#chapter-03) | Inventory is the scope input for every threat model. |
| [Model and Provider Risk](/handbook/2026#chapter-08) | Confirm provider terms and approval per entry. |
| [Governance Evidence and Customer Trust](/handbook/2026#chapter-14) | Inventory is the source of record for governance claims. |
AI SECURITY ENGINEERING FIELD GUIDE · 02
Architecture and Trust Boundaries
An LLM app is still an application. Review the glue code, not only the model.
“Every point where authority changes is where a control must live.”
Architecture review
Trace the complete request path — caller through outputs and side effects — and confirm enforcement lives at every trust boundary, not inside the model.
Map the request path before testing any behavior: authentication, authorization, prompt and context assembly, retrieval, model/provider call, tool orchestration, output handling, side effects, logging. The model call is one step in a larger path that includes session state, secrets, retries, and downstream state changes.
Map four flows separately: data flow, instruction flow, control flow, authority flow. A system that looks secure in one overlay often exposes a gap in another.
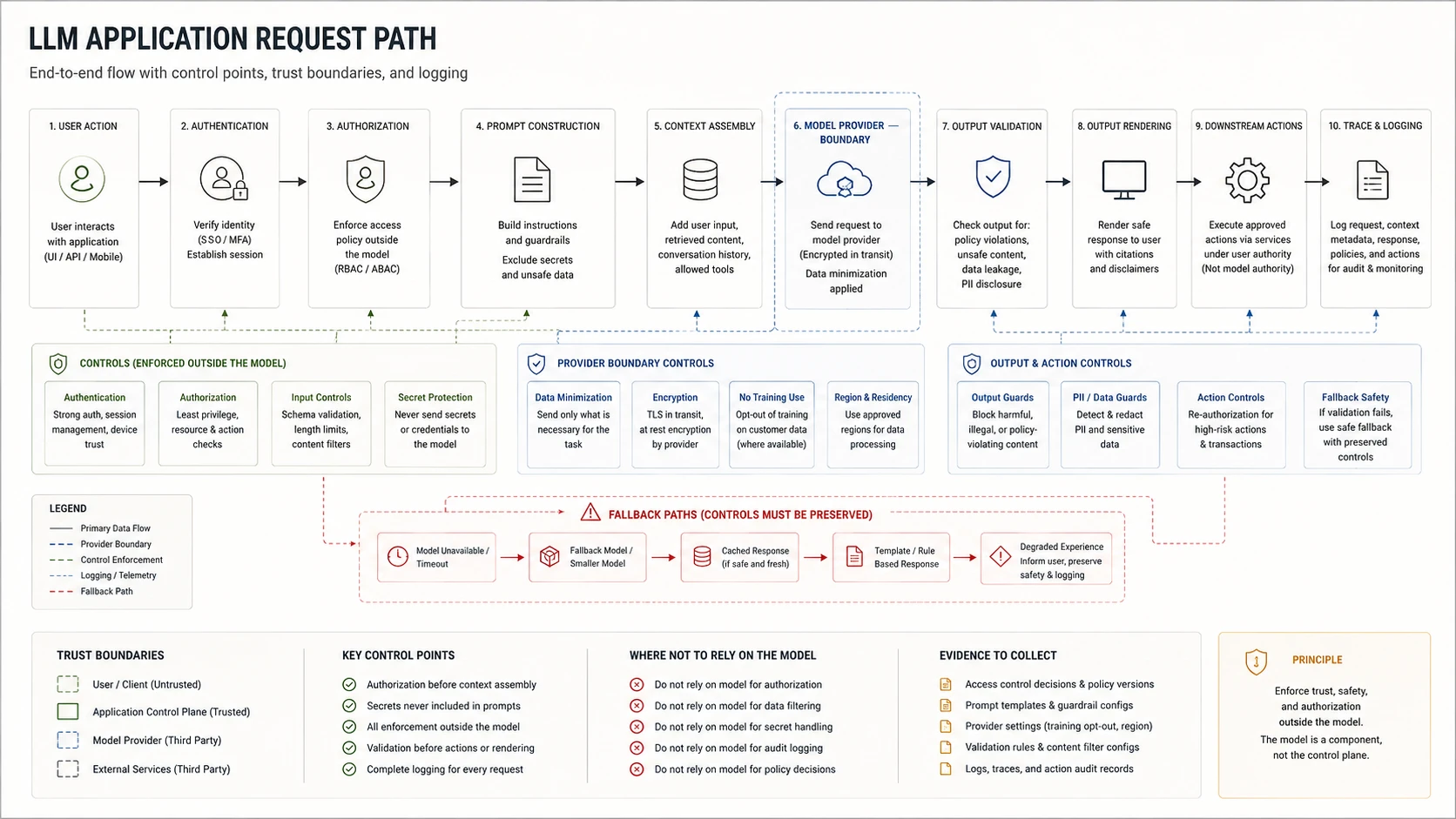
When to use: Architecture review, design review, new feature launch, model/provider/retrieval/tool changes, incident scope definition.
MAP
MAP
ATTACK
ATTACK
- Submit requests that skip authentication or authorization before model or tools.
- Send a low-privilege identity into paths requiring elevated authority; verify the check fires before the model.
- Inject untrusted content and verify it cannot change authorization or tool parameters.
- Force provider errors and fallback routes; verify logging and authorization persist.
- Submit malicious markdown, HTML, JSON, and code through the output path.
- Replay requests across roles, tenants, and feature flags for consistent enforcement.
- Check for secret exposure through prompt echo, debug output, or errors.
- Look for emergency-bypass paths that skip standard controls.
DEFEND
DEFEND — Required baseline
- Deterministic authorization before model, retrieval, provider, and tool calls — never delegated to model reasoning.
- Scoped identities: application, retrieval, tool, and provider identities are separate and least-privilege.
- Prompt construction standards: secrets excluded, untrusted content labeled.
- Output encoding, schema validation, and content policy checks before rendering.
- AI trace logging: request ID, model, prompt version, policy decision, identity, output handling.
- Release gates on prompt, provider, output-sink, and tool-authority changes.
DEFEND — High-risk and advanced
- High-risk systems
- Trust-boundary document: every authority-change point named, owned, enforced.
- Separate trust levels for user input, retrieved content, tool output, model output.
- Fallback paths preserve authorization and logging or refuse to serve.
- Advanced maturity
- Independent defense layers with distinct failure modes.
- Automated boundary-violation detection in telemetry.
Stop-ship conditions
- No complete, traceable request path from caller to output and side effects.
- Authorization relies on model reasoning or output parsing.
- Executing identity for tool calls is unknown or shared.
- Privileged side effect lacks policy enforcement.
Escalate when
EVIDENCE
EVIDENCE
- Design: request-path diagram with flow overlays, trust-boundary document.
- Implementation: authorization check locations, prompt construction standards.
- Validation: boundary bypass and authority confusion test results.
- Runtime: trace sample with identity, decision, model ID, output handling.
- Governance: release gate results, exception records.
Minimum evidence package
Request-path diagram, trust-boundary document, authorization test results, trace sample. Block approval if any boundary is undocumented or authorization delegates to the model.
Field decision questions
- Which identity actually executes each tool call?
- Where is authorization evaluated — before or after the model sees the request?
- What happens to authorization and logging when the primary path fails?
- Can a trace reconstruct identity, decision, context, output, and side effect?
Outputs
- Request-path diagram.
- Trust-boundary document.
- Authorization test results.
- Provider boundary statement.
Related domains
| Domain | When to consult |
|---|---|
| [AI System Inventory](/handbook/2026#chapter-01) | Confirm scope: every system here must be inventoried. |
| [Threat Modeling](/handbook/2026#chapter-03) | Use the request path as threat-model scope input. |
| [Prompt Injection](/handbook/2026#chapter-04) | Test untrusted content at every identified boundary. |
| [Agentic Permissions](/handbook/2026#chapter-06) | Resolve execution identity at every tool boundary. |
AI SECURITY ENGINEERING FIELD GUIDE · 03
Threat Modeling
Inspect
System, developer, user, retrieved, tool, and memory context boundaries.
Test
Direct injection, indirect injection, tool-output injection, memory persistence, and policy bypass.
“Name the exact trust boundary the attacker crosses before designing a control.”
Threat model review
Identify unacceptable outcomes, trace the attack paths that reach them, and assign a control and a residual-risk owner to each path before release.
Threat modeling runs at initial design, at scope change — new model, retrieval source, tool, provider — and after incidents. Model behavior is part of the attack surface: an LLM that can be prompted to bypass policy or disclose context is part of the attack path, not just an inference engine.
Test: can the team name the top three paths by which an attacker reaches an unacceptable outcome, name the control at each, and name who owns residual risk? If not, the threat model is not actionable.
When to use: Initial design, model/provider/retrieval/tool change, new user population, new data class, post-incident, any change introducing a new trust boundary.
MAP
MAP
ATTACK
ATTACK
- Enumerate abuse paths by actor: external attacker, malicious user, compromised provider, insider.
- Trace each path to an outcome: asset reached, boundary crossed, control that would stop it.
- Identify indirect paths: content entering through retrieval or tool results that influences behavior.
- Model provider-compromise paths and chained-action sequences.
- Test data-extraction paths through crafted prompts or retrieval queries.
- Review each path against existing controls; mark paths with none or model-compliance-only controls.
DEFEND
DEFEND — Required baseline
- Threat model document per high-risk system: scope, assets, actors, boundaries, abuse paths, controls, residual risk.
- Change-trigger list requiring threat model update before release.
- Every abuse path has a named control or an accepted residual risk with an owner.
- Threat model review required at release gate for model, provider, retrieval, or tool-scope changes.
DEFEND — High-risk and advanced
- High-risk systems
- Threat model is a required design-review artifact, not a post-hoc exercise.
- Cross-domain modeling: injection, RAG, and agentic abuse paths modeled together.
- Control validation evidence for each mapped control.
- Advanced maturity
- Automated change-trigger detection in CI/CD.
- Threat model linked directly to Detection Engineering hypotheses.
Stop-ship conditions
- No threat model for a high-risk system entering production.
- Tool authority or retrieval trust level omitted from scope.
- No abuse cases documented — only generic risk categories.
- No control assigned to an enumerated abuse path.
Escalate when
EVIDENCE
EVIDENCE
- Design: threat model document, change-trigger list.
- Implementation: control assignments traceable to abuse paths.
- Validation: control validation results, negative tests.
- Governance: risk acceptance records, release gate record.
Minimum evidence package
Threat model document, change-trigger list, control-assignment table, risk acceptance records. Block release if any high-risk path has no control and no accepted residual risk.
Field decision questions
- What are the top three paths to an unacceptable outcome in this system?
- Which trust boundaries have no deterministic control?
- What change would require the threat model to be updated?
- Who owns residual risk for unmitigated paths?
Outputs
- Threat model document.
- Abuse-path register with control assignments.
- Change-trigger list.
- Risk acceptance records.
Related domains
| Domain | When to consult |
|---|---|
| [AI System Inventory](/handbook/2026#chapter-01) | Confirm full system scope before modeling starts. |
| [Architecture and Trust Boundaries](/handbook/2026#chapter-02) | Use the request-path map as threat-model input. |
| [Prompt Injection](/handbook/2026#chapter-04) | Model injection as an explicit abuse path. |
| [Evaluation and Regression Testing](/handbook/2026#chapter-13) | Derive the adversarial test plan from abuse paths. |
AI SECURITY ENGINEERING FIELD GUIDE · 04
Prompt Injection
Retrieval is a data access decision. Treat it as one.
“Treat untrusted context as data. Never let it become authority.”
Injection review
Identify every untrusted content source entering the context window and verify no lower-authority source can change a higher-authority decision, tool call, or policy outcome.
Prompt injection is an instruction-hierarchy violation, not a jailbreak against model policy. A jailbreak targets trained behavior. Injection targets the control plane: adversarial content in a lower-trust source influences instructions, tool parameters, or policy decisions belonging to a higher-trust source.
The question is not whether the model can be tricked in isolation — it is what the injected content can reach. A poisoned ticket that changes a tool call or modifies memory is a finding regardless of whether the final answer looks benign.
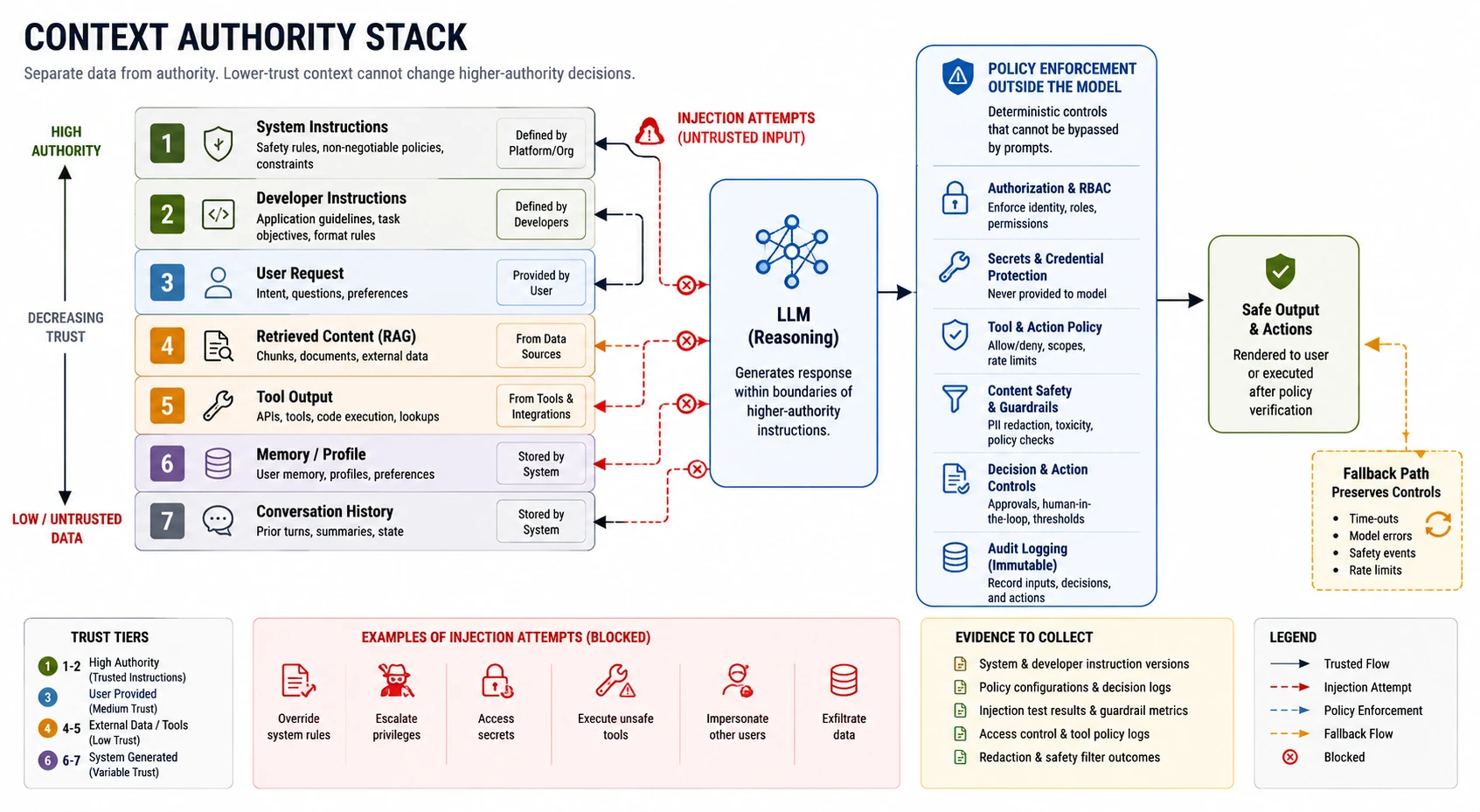
When to use: Any system incorporating untrusted input into context — user messages, retrieved documents, tool results, external URLs, email, uploaded files.
MAP
MAP
ATTACK
ATTACK
- Direct injection through user input; verify it cannot override system instructions or escalate authority.
- Indirect injection via documents, tickets, files, and tool results; verify it cannot reach privileged paths.
- Instruction-conflict cases across system, developer, user, and retrieval layers.
- Exfiltration attempts that try to route sensitive context to an output channel.
- Tool-result injection that attempts to change subsequent tool calls.
- Unsafe structured output: malformed JSON, SQL, or shell commands reaching an interpreter.
- Cross-turn persistence through memory or cached context.
DEFEND
DEFEND — Required baseline
- Privilege separation: authorization enforced by deterministic code, not model interpretation.
- Source labeling: every untrusted source labeled so data is distinguishable from instruction.
- Authorization outside the model: tool parameters and policy decisions evaluated by a policy engine.
- Output validated for schema conformance before reaching an interpreter or executor.
- Regression tests for injection scenarios on every release touching prompt, retrieval, or tools.
DEFEND — High-risk and advanced
- High-risk systems
- Context isolation: retrieval, tool, and user segments assembled separately with distinct rules.
- Capability restriction: minimum tools exposed to untrusted-content paths.
- Approval gates for privileged calls that cannot be bypassed by model reasoning.
- Advanced maturity
- Structural context separation parsed into separate structs before reaching the model.
- Automated injection regression suite covering every active retrieval source.
Stop-ship conditions
- Untrusted content can directly control privileged tool parameters with no policy check.
- No indirect-injection testing against active retrieval sources.
- Model output reaches a shell, executor, or SQL engine without validation.
- Authorization for a privileged action depends on model compliance.
Escalate when
EVIDENCE
EVIDENCE
- Design: context authority diagram, threat model section on injection.
- Implementation: authorization check locations, source-labeling record.
- Validation: direct and indirect injection test results, output-handling tests.
- Runtime: log samples with source labels and tool-call parameters.
Minimum evidence package
Direct and indirect injection test results, context authority diagram, authorization check locations, regression suite execution record. Block release if indirect injection testing has not been performed.
Field decision questions
- Which is the lowest-trust source entering context, and can it influence a tool call?
- Is authorization for every privileged action deterministic, or model-dependent?
- Which output paths reach an interpreter, and what validates them?
- What change to retrieval sources would require injection testing to rerun?
Outputs
- Context authority diagram.
- Injection test results register.
- Regression test suite.
- Findings backlog.
Related domains
| Domain | When to consult |
|---|---|
| [Architecture and Trust Boundaries](/handbook/2026#chapter-02) | Confirm trust boundaries before classifying sources. |
| [RAG Authorization](/handbook/2026#chapter-05) | Retrieval is the primary indirect injection vector. |
| [Agentic Permissions](/handbook/2026#chapter-06) | Injected tool parameters are the highest-severity outcome. |
| [Detection Engineering](/handbook/2026#chapter-11) | Injection attempts should generate detectable telemetry. |
AI SECURITY ENGINEERING FIELD GUIDE · 05
RAG Authorization
Authority
Agent security
Map what the agent can read, write, send, execute, purchase, delete, approve, and administer.
“Semantic similarity determines relevance. It does not grant access.”
RAG authorization review
Verify authorization runs before content enters the context window — not after the model decides what to include in its answer.
Retrieval leaks happen at the retrieval step, not generation. A chunk a caller should not see enters context the moment it is retrieved and ranked — the answer is the symptom, not the failure. If a chunk enters context before authorization is confirmed, the access already occurred.
Start with pre-retrieval eligibility, not answer quality. Trace which chunks entered context for a query and verify the caller was authorized for each. Retrieval logs must show source identity, tenant, authorization decision, rank order, and final chunk set.
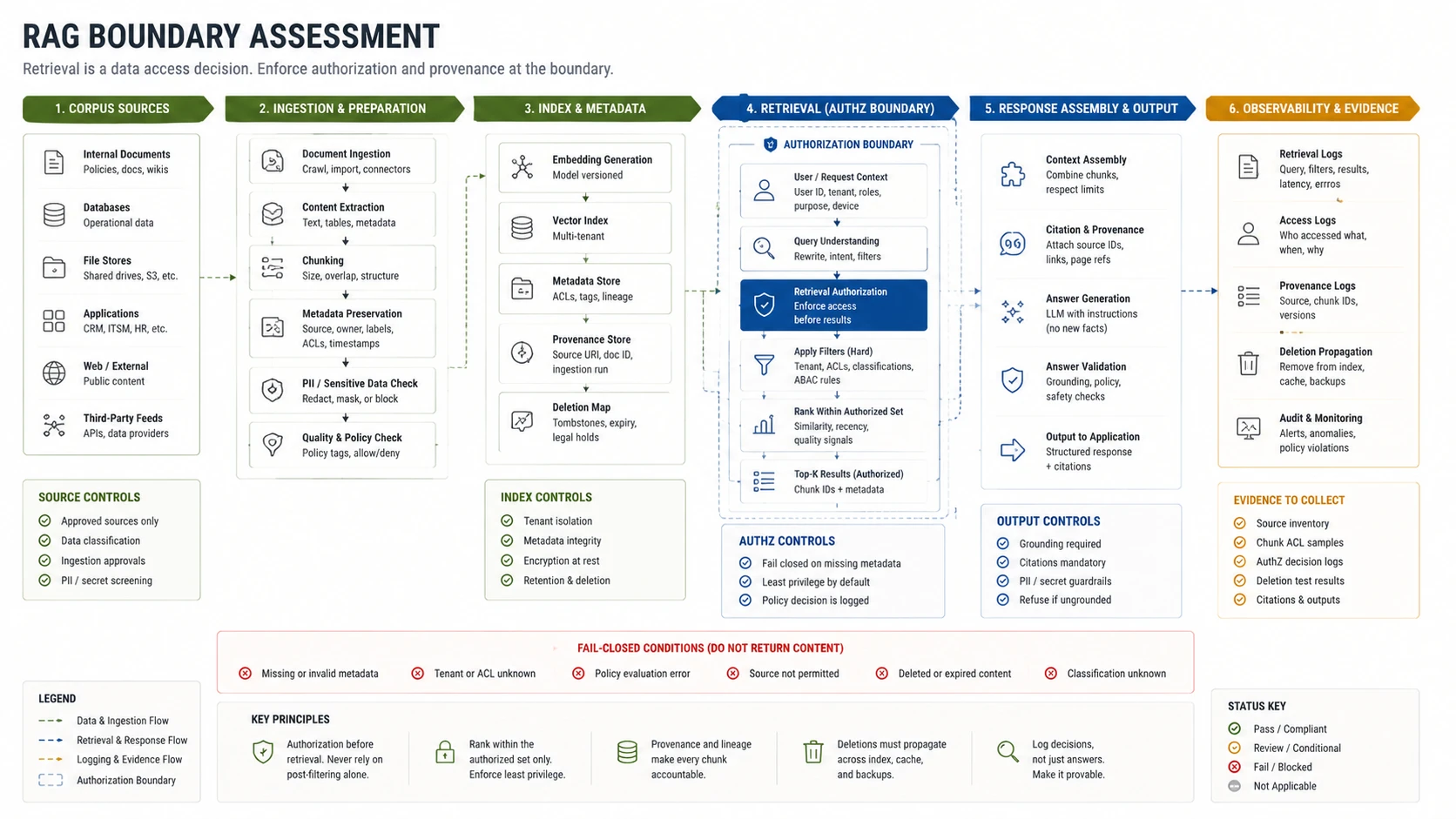
When to use: Any system using retrieval-augmented generation, vector search, document Q&A, or hybrid search.
MAP
MAP
ATTACK
ATTACK
- Cross-tenant retrieval: query as Tenant A, attempt to retrieve Tenant B's chunks.
- Metadata bypass: craft high-similarity queries against restricted chunks.
- Stale ACL: change a document's permissions, re-query before re-indexing.
- Poisoned document ingestion and detection before serving.
- Index desync: delete or reclassify a document, verify removal within SLA.
- Query rewriting or reranking that drops or reorders authorization filters.
- Fail-closed: corrupt chunk metadata and verify the chunk is excluded, not served.
DEFEND
DEFEND — Required baseline
- Pre-retrieval eligibility: authorization evaluated before ranking, not after.
- Tenant filtering from authenticated session, applied before retrieval.
- Fail-closed retrieval: missing metadata excludes the chunk.
- Deletion and reclassification propagation with a defined SLA and verification.
- Retrieval logging: source ID, tenant, authorization decision, rank, final chunk set.
DEFEND — High-risk and advanced
- High-risk systems
- Row or document-level controls, not only collection-level access.
- Source provenance carried into context for downstream logging.
- Negative tests in regression: cross-tenant and deleted-document cases every release.
- Advanced maturity
- Real-time ACL synchronization within seconds of source changes.
Stop-ship conditions
- Authorization occurs after sensitive content enters context.
- The pipeline cannot enforce tenant scope.
- Document identity cannot be traced to a source record.
- Cross-tenant retrieval tests return wrong-tenant chunks.
Escalate when
EVIDENCE
EVIDENCE
- Design: authorization design document, chunk metadata schema.
- Implementation: filter configuration, tenant-isolation record, deletion job config.
- Validation: cross-tenant and stale-ACL test results, fail-closed test.
- Runtime: retrieval log samples with authorization decisions per request.
Minimum evidence package
Authorization design document, cross-tenant test results (zero unauthorized chunks), deletion propagation test, retrieval log sample. Block approval if pre-retrieval enforcement is unclear.
Field decision questions
- At exactly which step does authorization run — before or after ranking?
- Can the team show which chunks entered context for a past query?
- What happens if chunk metadata is missing or corrupted?
- How long until a deleted document leaves the index, and how is that verified?
Outputs
- RAG authorization design document.
- Corpus source map.
- Cross-tenant and stale-ACL test results.
- Deletion propagation verification record.
Related domains
| Domain | When to consult |
|---|---|
| [Prompt Injection](/handbook/2026#chapter-04) | Retrieved chunks are the primary indirect injection vector. |
| [Data Exposure and Privacy](/handbook/2026#chapter-07) | Confirm data classification and deletion rights per source. |
| [Logging and Telemetry](/handbook/2026#chapter-10) | Retrieval logs must capture chunk identity and authorization decision. |
| [Detection Engineering](/handbook/2026#chapter-11) | Cross-tenant attempts should generate detectable telemetry. |
AI SECURITY ENGINEERING FIELD GUIDE · 06
Agentic Permissions
Inspect
Model source, license, hash, loader, dependency, dataset, registry, and promotion path.
Produce
AI bill of materials, provenance record, license review, and registry control notes.
“An agent inherits the authority of its execution identity, not the intent of its instructions.”
Agency review
Map every tool, execution identity, side effect, approval gate, and revocation path before the first test prompt.
Agentic systems call tools, browse, query data, send messages, and trigger workflows. A helpdesk bot that can reset access or post a Slack message is delegated action with real side effects, not a chat interface. The scope of that delegation is set by execution identity, not the system prompt.
The question is concrete: which identity does the runtime use when the agent reaches for a tool? If shared across users, or broader than the user's own authority, the boundary is wrong.
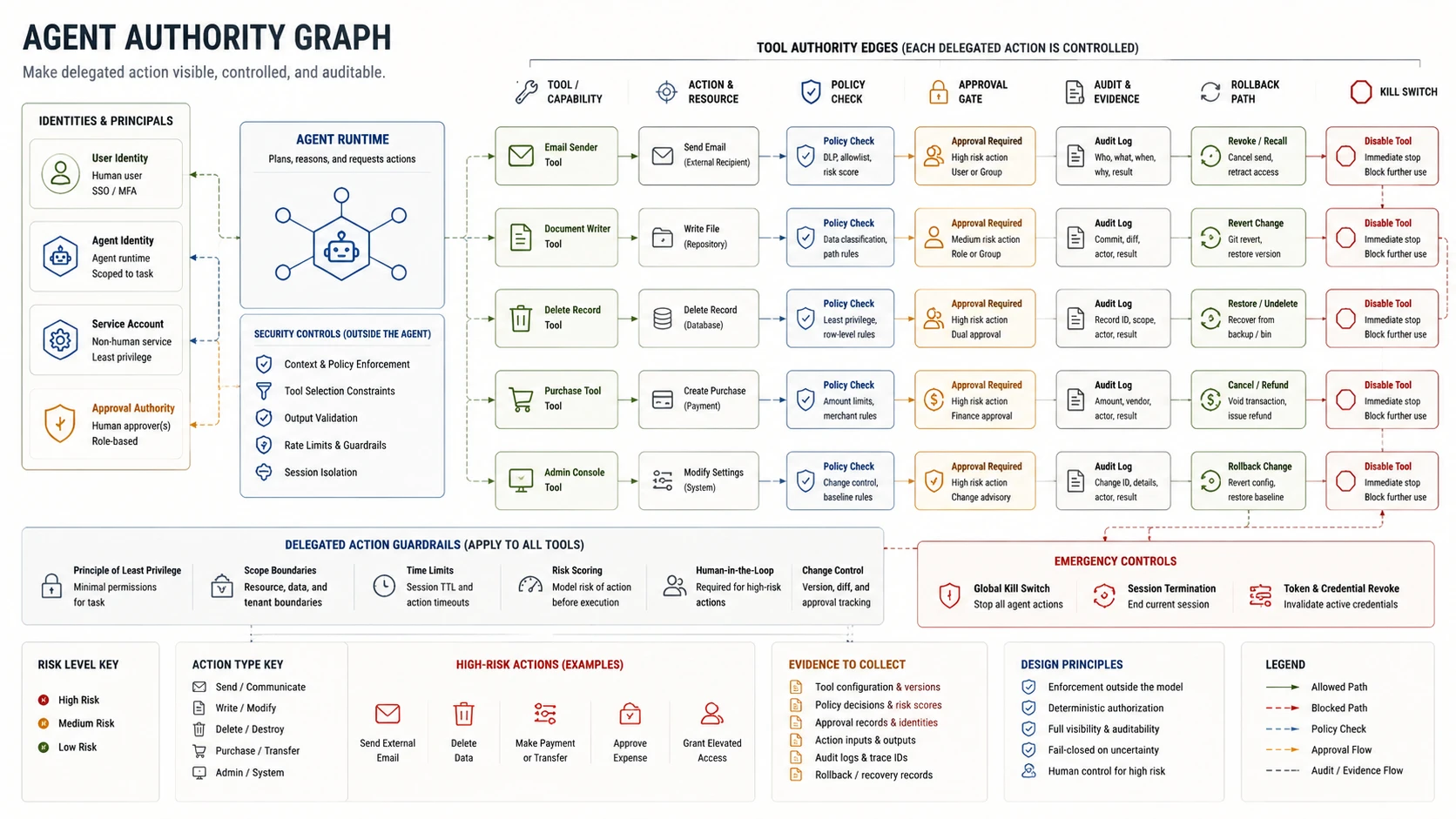
When to use: Any system invoking tools or triggering state changes — agents, tool-using copilots, automated workflows.
MAP
MAP
ATTACK
ATTACK
- Unauthorized tool calls with an identity that should not have access.
- Parameter manipulation via injected tool results.
- Chained escalation: individually permitted steps combining into an unauthorized outcome.
- Confused deputy: agent acting with service-account authority beyond user permission.
- Approval bypass for destructive, financial, or irreversible actions.
- Credential exposure through prompts, errors, or logs.
- Excessive retries triggering a runaway loop.
DEFEND
DEFEND — Required baseline
- Tool allowlist: only explicitly approved tools, no dynamic discovery at runtime.
- Scoped execution identities: dedicated, least-privilege per tool — no shared broad tokens.
- Policy engine outside the model evaluates tool authorization.
- Approval gates for destructive, financial, external, or irreversible actions.
- Rate and monetary limits enforced at the tool layer.
- Emergency revocation procedure executable within minutes.
- Complete action traces: tool, parameters, identity, decision, result, trace ID.
DEFEND — High-risk and advanced
- High-risk systems
- Sandboxing for tools that execute code or call external APIs.
- Reversibility preference with step-up approval for irreversible actions.
- Separate user and agent identity — the agent never escalates user authority.
- Advanced maturity
- Just-in-time tool provisioning with automatic credential expiry.
- Behavioral baseline monitoring on tool-call sequences.
Stop-ship conditions
- A high-risk tool runs under a broad shared credential.
- A model-generated tool call executes without deterministic policy evaluation.
- A destructive or irreversible action has no approval gate.
- No emergency revocation procedure exists.
Escalate when
EVIDENCE
EVIDENCE
- Design: agent authority graph, tool permission matrix.
- Implementation: allowlist config, identity scoping, approval gate context shown to approver.
- Validation: unauthorized-call and approval-bypass test results, revocation drill.
- Runtime: tool-call log samples with execution identity and trace ID.
Minimum evidence package
Agent authority graph, tool permission matrix, policy engine config, unauthorized-call test results, tool-call log sample. Block approval if any tool lacks a scoped identity or a destructive action has no approval gate.
Field decision questions
- Which identity does the runtime use for each tool call?
- What can the agent do that the user cannot do directly?
- Can the team halt all tool execution within five minutes of an incident?
- What is the rollback path after a destructive action?
Outputs
- Agent authority matrix.
- Tool permission review.
- Permission abuse test results.
- Revocation drill record.
Related domains
| Domain | When to consult |
|---|---|
| [Architecture and Trust Boundaries](/handbook/2026#chapter-02) | Confirm execution identity and tool boundaries in the architecture. |
| [Prompt Injection](/handbook/2026#chapter-04) | Tool parameters influenced by injected content are highest severity. |
| [Incident Response](/handbook/2026#chapter-12) | Tool revocation and rollback are containment actions. |
AI SECURITY ENGINEERING FIELD GUIDE · 07
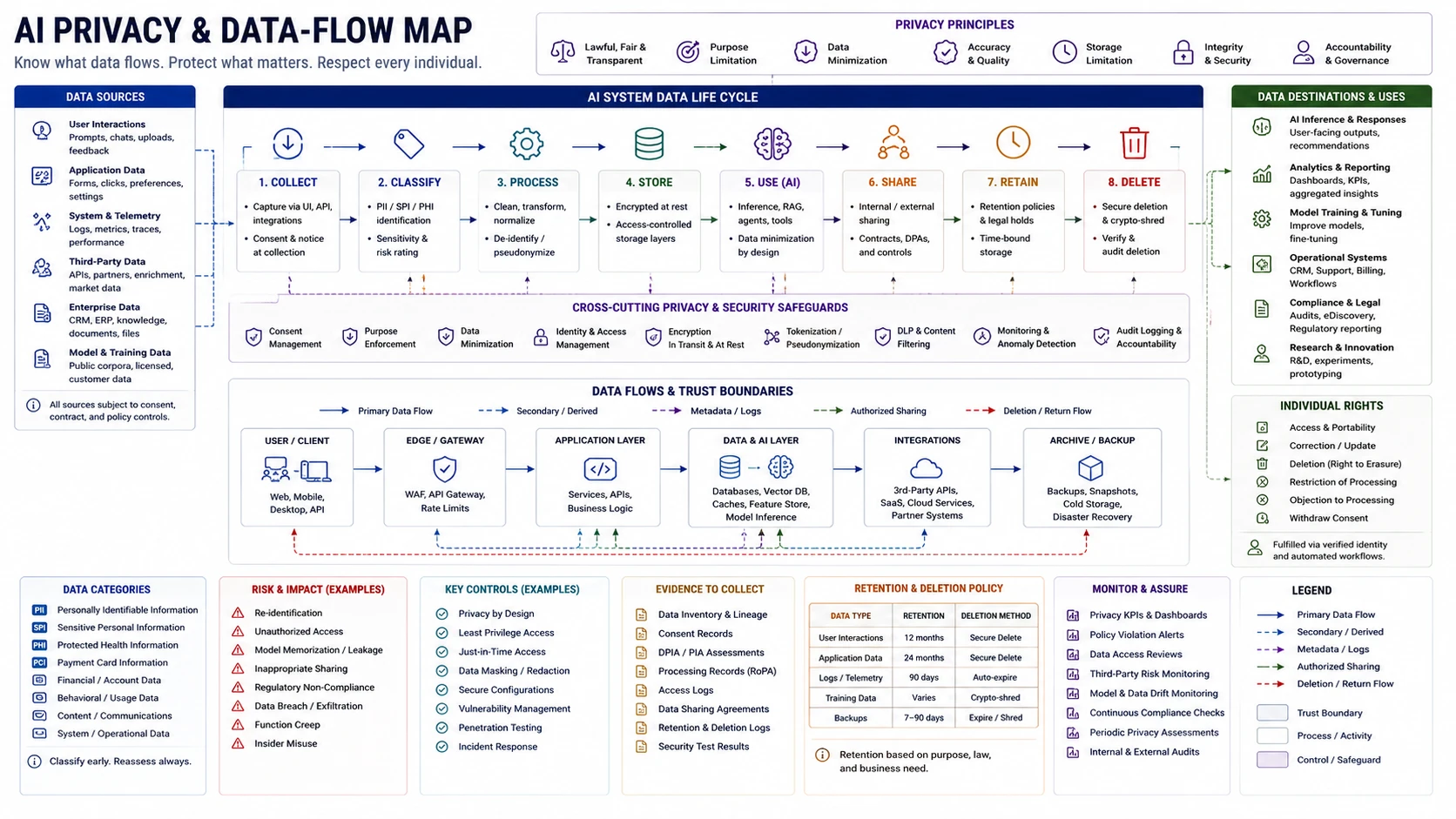
Data Exposure and Privacy
MLOps risk lives in pipelines, notebooks, registries, credentials, and serving paths.
“Deletion is incomplete until every derived record — prompts, embeddings, logs, memory — is purged.”
Data exposure review
Trace sensitive data from source collection through every derived record and confirm deletion reaches all of them.
AI systems create derived data not present in the source record: prompts with personal information, embedding vectors encoding sensitive content, support logs capturing conversation history. These persist independently after the source is deleted. A review that stops at the source record misses most of the exposure surface.
Confirm provider processing terms before sensitive data crosses the provider boundary. Unknown provider data-use commitments are a stop-ship condition regardless of data class.

When to use: Any AI feature processing personal, confidential, or regulated data — design review, provider onboarding, new data sources or logging changes.
MAP
MAP
ATTACK
ATTACK
- Prompt and log leakage: submit sensitive data, check logs for unredacted exposure.
- Cross-user exposure: attempt to retrieve another user's prompt history or memory.
- Provider retention: verify the live setting matches committed terms, not the questionnaire.
- Training reuse: confirm customer data is not used for provider training without consent.
- Embedding exposure: attempt to extract recoverable personal data from the store.
- Deletion propagation: submit a request, then check prompts, embeddings, logs, caches, memory.
DEFEND
DEFEND — Required baseline
- Data minimization: sensitive data excluded from prompts and provider calls unless required.
- Provider data-use terms reviewed before onboarding: retention, training opt-out, sub-processors, regions.
- Sensitive data classification for prompts, embeddings, memory, logs, eval fixtures.
- Retention and deletion covering all derived records within a defined SLA.
- Role-based access controls and audit logging on AI trace logs.
DEFEND — High-risk and advanced
- High-risk systems
- Regional processing controls with verified provider routing.
- Sub-processor records with notification commitments.
- Privacy review gate for material data-flow or provider changes.
- Advanced maturity
- Real-time derived-record inventory across all record types.
Stop-ship conditions
- Provider data-use terms are unknown or unreviewed.
- Secrets or PII routinely enter prompt logs without access controls.
- No deletion workflow covers derived AI records.
- A deletion request cannot be fulfilled for any derived record type.
Escalate when
EVIDENCE
EVIDENCE
- Design: data-flow diagram, provider processing terms.
- Implementation: minimization config, retention and deletion job config.
- Validation: deletion propagation tests per derived record type, log leakage tests.
- Governance: derived-record inventory, data processing agreements.
Minimum evidence package
Data-flow diagram, provider processing terms, deletion propagation test results for all derived record types. Block approval if any derived record type is uncovered by deletion.
Field decision questions
- Which derived records does this system create, and is each covered by deletion?
- What does the provider's live retention setting show?
- Can a user's data be deleted from prompts, embeddings, logs, and memory?
- What sensitive data minimally needs to enter each derived record?
Outputs
- AI data-flow map.
- Provider processing terms review.
- Deletion propagation test results.
- Derived-record inventory.
Related domains
| Domain | When to consult |
|---|---|
| [RAG Authorization](/handbook/2026#chapter-05) | Confirm data classification and deletion coverage at ingestion. |
| [Model and Provider Risk](/handbook/2026#chapter-08) | Provider data-use terms reviewed alongside risk assessment. |
| [Logging and Telemetry](/handbook/2026#chapter-10) | Log access controls implement this domain's requirements. |
AI SECURITY ENGINEERING FIELD GUIDE · 08
Model and Provider Risk
Inspect
Intake, design review, threat-model triggers, eval gates, exceptions, backlog, and retest evidence.
Decision
A launch gate is useful only when it changes release behavior.
“A provider change is a product security event, not a platform update.”
Provider risk review
Confirm the model and provider in use are approved, terms are reviewed, behavior changes are monitored, and a fallback exists for critical use cases.
Provider risk is ongoing. A provider can change model behavior silently, alter retention, shift regional processing, or expand sub-processors after the initial agreement. Review the live configuration, not the questionnaire submitted at purchase.
The question: if the provider changes model behavior, retention, or routing tomorrow, will the team know, and what is the response?
When to use: Provider onboarding, model version change, contract renewal, customer assurance review, retention or sub-processor changes.
MAP
MAP
ATTACK
ATTACK
- Silent model change: run a baseline eval set, simulate a version change, check for regression detection.
- Provider outage: verify fallback engages and preserves authorization and logging.
- Region failover: verify it does not route data to a prohibited region.
- Contract mismatch: compare questionnaire, trust-center claims, and actual contract language.
- Evidence access: verify the team can obtain logs and audit records the provider committed to.
- Lock-in: verify prompts and eval sets can be exported to an alternative provider.
DEFEND
DEFEND — Required baseline
- Approved-provider process reviewing data-use terms, security commitments, regional controls.
- Data processing agreement executed before sensitive data transmission.
- Behavior change monitoring: an eval set runs at a defined cadence; regression triggers review.
- Fallback provider or path for critical use cases, defined and tested.
- Incident notification clause with a defined response window.
DEFEND — High-risk and advanced
- High-risk systems
- Version pinning where available; tighter monitoring cadence if floating.
- Portability verification: data export exercised and migration confirmed feasible.
- Periodic reassessment at contract renewal and after material provider change.
- Advanced maturity
- Continuous behavioral monitoring sampling model output against the baseline.
Stop-ship conditions
- Provider data-use terms are unknown or unreviewed in the current contract.
- No fallback path exists for a critical production use case.
- No process exists to detect a silent model behavior change.
- Security incident notification requirements are undefined.
Escalate when
EVIDENCE
EVIDENCE
- Design: provider intake record, fallback design document.
- Implementation: executed data processing agreement, retention configuration.
- Validation: behavior change monitoring results, portability test, fallback drill.
- Governance: periodic reassessment record, contract renewal review.
Minimum evidence package
Provider intake record, executed data processing agreement, behavior change monitoring results, fallback design document. Block approval if provider terms are unreviewed or no fallback exists.
Field decision questions
- What does the provider's live retention setting show?
- What is the response plan if the provider changes model behavior?
- Which use cases fail if the provider is unavailable for 24 hours?
- Can the team migrate to an alternative provider within the portability window?
Outputs
- Provider intake and approval record.
- Behavior change monitoring baseline.
- Fallback design document.
- Provider risk summary.
Related domains
| Domain | When to consult |
|---|---|
| [AI System Inventory](/handbook/2026#chapter-01) | Every inventoried system includes a provider record. |
| [Data Exposure and Privacy](/handbook/2026#chapter-07) | Provider data-use terms determine privacy sufficiency. |
| [Evaluation and Regression Testing](/handbook/2026#chapter-13) | Behavior monitoring relies on evaluation infrastructure. |
AI SECURITY ENGINEERING FIELD GUIDE · 09
AI Supply Chain
AI privacy review starts where source data becomes prompts, embeddings, logs, memory, and derived records.
“An artifact without provenance cannot be trusted, rolled back, or investigated.”
Supply chain review
Confirm every artifact entering production — weights, adapters, loaders, packages, prompts, eval sets, datasets — has traceable provenance, a verified hash, and a rollback path.
Supply chain risk extends beyond model weights to tokenizers, loaders, serialization formats, embedding pipelines, prompt templates, evaluation fixtures, and retrieval connectors. Any can be tampered with or substituted without detection if provenance tracking stops at the model download.
Trace one artifact from source through pipeline stages, registry promotion, and production deployment. If any step lacks a verified hash, a named approver, and a rollback procedure, it is not production-ready.
When to use: New model or adapter adoption, connector additions, package updates, prompt template changes, dataset additions, CI/CD pipeline changes.
MAP
MAP
ATTACK
ATTACK
- Poisoned artifact: modify contents without regenerating the approved hash; verify the check catches it.
- Unsafe serialization: load a pickle-format artifact in isolation and verify it cannot execute code in production.
- Tampered weights: substitute an artifact that passes name checks but fails hash verification.
- Malicious package and dependency confusion in the build pipeline.
- Unreviewed adapter promotion attempt without a review record.
- Registry bypass: attempt deployment without the promotion gate.
DEFEND
DEFEND — Required baseline
- Artifact provenance: source, version, download path, and approver recorded.
- Hash verification at download and promotion — no artifact moves without a match.
- Approved-source policy for models, adapters, datasets, and loaders.
- Safe loading only: pickle-based loading blocked in production inference.
- Registry RBAC and promotion gates with recorded approval and rollback plan.
DEFEND — Cross-cutting lenses and advanced
- MLOps lens
- Environment isolation: training, evaluation, staging, production have separate identities.
- Separation of duties: train, approve, and deploy require different identities.
- Secure SDLC lens
- Code review for model loading, embedding, retrieval, and tool-definition code.
- Change triggers on prompt, dataset, and eval-set updates matching model-change gates.
- High-risk systems
- Signature verification at promotion and load time; sandboxed loading before promotion.
- Advanced maturity
- Software bill of materials per release; continuous dependency vulnerability monitoring.
Stop-ship conditions
- Artifact provenance is unknown for a production artifact.
- Unsafe serialization is used in the production inference path.
- A production deployment bypasses the registry promotion gate.
- No rollback path exists for the production artifact.
Escalate when
EVIDENCE
EVIDENCE
- Design: approved-source policy, separation-of-duties policy.
- Implementation: registry RBAC config, hash verification record.
- Validation: hash verification tests, safe-format loading rejection test, rollback drill.
- Governance: artifact manifest per release.
Minimum evidence package
Artifact provenance records with hash, registry promotion log with approver identity, safe-format verification, rollback test record. Block approval if any production artifact lacks a traceable source.
Field decision questions
- Can the team show source, approver, and hash for every production artifact?
- What code executes when the model artifact loads?
- Who can promote to production, and is that limited to authorized identities?
- What is the rollback procedure if an artifact is found tampered?
Outputs
- AI artifact bill of materials.
- Provenance and integrity records.
- Registry promotion review.
- Rollback drill record.
Related domains
| Domain | When to consult |
|---|---|
| [Model and Provider Risk](/handbook/2026#chapter-08) | Provider-hosted models are supply chain components too. |
| [Evaluation and Regression Testing](/handbook/2026#chapter-13) | Eval sets are supply chain artifacts requiring provenance. |
| [Incident Response](/handbook/2026#chapter-12) | Supply chain compromise requires specific containment steps. |
AI SECURITY ENGINEERING FIELD GUIDE · 10
Logging and Telemetry
Evidence
Governance evidence
Map policy statements to controls, owners, tests, telemetry, and public-safe evidence.
“If the trace cannot reconstruct what the model saw, retrieved, and decided, it cannot support an investigation.”
Telemetry review
Verify structured traces capture every identity, authorization decision, retrieved document, tool call, and side effect — correlated, with access controls on sensitive content.
AI logging has two functions: evidence for investigation and input for detection. Evidence logging must cover every identity, decision, and side effect, and resist tampering. Detection logging must be structured and correlated. Conflating the two produces systems that are verbose but not investigable.
Baseline requirement: a trace must reconstruct identity, context assembled, authorization decisions, retrieved chunks, tool calls, model output, and side effects — from a single correlation ID.

When to use: Architecture review, release gating for any AI feature, incident preparation, detection engineering setup.
MAP
MAP
ATTACK
ATTACK
- Submit requests across every active path; verify all expected events appear.
- Trace one request across log sources; verify correlation holds end to end.
- Verify production log storage cannot be modified by application-layer identities.
- Examine logs for unredacted secrets, PII, or sensitive prompt content.
- Cross-tenant log exposure: query as one tenant, check for another tenant's content.
- Simulate a provider timeout or tool error; verify the failed step is still recorded.
DEFEND
DEFEND — Required controls
- Structured schemas with identity, resource, action, decision, outcome, correlation ID.
- A single correlation ID propagating through application, retrieval, model, and tool layers.
- Role-based access controls and audit logging on logs containing prompt or output content.
- Redaction of credentials and PII before storage where feasible.
- Defined retention per log tier, minimum 90 days for security-relevant events.
- Retrieval records, tool-call records, and side effects as required fields for high-risk systems.
Stop-ship conditions
- Privileged side effects cannot be reconstructed from logs.
- Actual executing identity for tool calls is absent from logs.
- Retrieved chunk IDs are not recorded.
- No correlation exists across model, retrieval, tool, and application events.
Escalate when
EVIDENCE
EVIDENCE
- Design: log schema specifications, retention tier definitions.
- Implementation: access control and redaction configuration per log source.
- Validation: trace reconstruction test, missing-event tests, cross-tenant isolation test.
- Runtime: trace sample with identity, decision, chunk IDs, tool calls, side effects.
Minimum evidence package
Log schema per source, trace reconstruction test result, access control configuration, trace sample showing a complete request. Block approval if any privileged side effect has no log record.
Field decision questions
- Can the team reconstruct a complete request from logs alone?
- Does the tool-call log identity match the actual execution identity?
- What happens to the trace on a retrieval or provider error?
- Who can access prompt and output logs, and is that access audited?
Outputs
- Log schema specifications.
- Trace reconstruction test results.
- Access control and redaction review.
- Telemetry gap register.
Related domains
| Domain | When to consult |
|---|---|
| [Architecture and Trust Boundaries](/handbook/2026#chapter-02) | Every boundary must generate required log events. |
| [RAG Authorization](/handbook/2026#chapter-05) | Retrieval logs must capture chunk IDs and authorization decisions. |
| [Detection Engineering](/handbook/2026#chapter-11) | Detection rules operate on logs produced here. |
| [Incident Response](/handbook/2026#chapter-12) | Evidence preservation depends on this domain's coverage. |
AI SECURITY ENGINEERING FIELD GUIDE · 11
Detection Engineering
Scope
Prompts, retrieval, tools, agents, policy bypass, data exposure, evidence capture, remediation, and retest.
Output
Scenario list, findings register, retest report, and regression backlog.
“A detection rule that has never been validated is a hypothesis, not a control.”
Detection review
Confirm each high-risk system has detection hypotheses, the required telemetry exists, every rule has an owner, and every rule has been validated.
Detection engineering requires explicit threat hypotheses translated into observable telemetry events: what behavior indicates a control failure, which log fields signal it, what threshold is actionable, and who triages.
This domain does not promise generic detection of all prompt injection. It provides a framework for engineering specific, testable, owned detection logic against your threat model's abuse paths.
When to use: Before production launch of any high-risk system, after threat model updates, after incidents revealing blind spots.
MAP
MAP
ATTACK
ATTACK
- Generate unauthorized retrieval as an unauthorized identity; verify the rule fires.
- Simulate approval bypass; verify the rule fires on the missing approval event.
- Execute a chained-escalation tool-call pattern; verify the sequence rule fires.
- Use a service identity at an unusual time or source; verify the behavioral rule fires.
- Trigger a repeated blocked action; verify the frequency threshold fires.
DEFEND
DEFEND — Required baseline
- Detection hypotheses per high-risk system: event, alert condition, threshold, owner, response action.
- Rule validation against real or synthetic matching events — not only normal traffic.
- Named triage owner with a defined response SLA per alert class.
- Pre-defined response action per alert class, from log-and-monitor to containment.
DEFEND — Examples and advanced
- Cross-tenant retrieval attempt: alert when a retrieval result's
tenant_iddoes not match the session tenant, regardless of whether the chunk was served. Severity high; alert security, log full context. - Abnormal tool chain: alert on escalation from read-only to write/admin tools within one session without a corresponding approval-gate event. Severity high; preserve full trace.
- High-risk systems
- Sequence rules for multi-step patterns, not only single events.
- Enrichment with user history and resource sensitivity before triage.
- Advanced maturity
- Continuous rule validation via synthetic event injection.
Stop-ship conditions
- A high-risk system has no detection hypotheses from its threat model.
- Required telemetry for a hypothesis is absent from logs.
- An alert class has no owner.
- A rule has never been validated against a matching event.
Escalate when
EVIDENCE
EVIDENCE
- Design: detection hypothesis register.
- Implementation: rule specifications, alert routing, response action definitions.
- Validation: rule validation test results, false-positive review.
- Runtime: alert records with triage actions and resolution.
Minimum evidence package
Detection hypothesis register, rule validation results per hypothesis, alert owner assignment, response action definitions. Block approval if any high-risk abuse path has no hypothesis and no accepted risk.
Field decision questions
- Which threat model abuse paths have no detection hypothesis?
- Has each rule been validated against a synthetic triggering event?
- Who triages each alert class, and what is the response SLA?
- When was each active rule last tuned or validated?
Outputs
- Detection hypothesis register.
- Rule validation test results.
- Alert triage and response definitions.
- Telemetry gap register.
Related domains
| Domain | When to consult |
|---|---|
| [Threat Modeling](/handbook/2026#chapter-03) | Abuse paths are the input for detection hypotheses. |
| [Logging and Telemetry](/handbook/2026#chapter-10) | Detection rules require specific log fields — confirm availability. |
| [Incident Response](/handbook/2026#chapter-12) | Detection is the handoff point into incident response. |
AI SECURITY ENGINEERING FIELD GUIDE · 12
Incident Response
You cannot investigate an AI incident from the final answer alone.
“You cannot investigate an AI incident from the final answer alone.”
Incident response review
Confirm the team can reconstruct prompt, context, retrieval, tool calls, policy decisions, and side effects from existing traces — and contain the system within minutes.
An investigation requires the complete execution chain, not the final output: what the model saw, what was retrieved, which tools ran under which identity, what policy decided, what changed. That chain must be visible in existing logs, not reconstructed from memory after the fact.
Tabletop exercises validate whether current telemetry is actually sufficient. Run one with a synthetic RAG leak or agent misuse event before launch — the pass condition is scoping impact and executing containment from existing logs and runbooks alone.
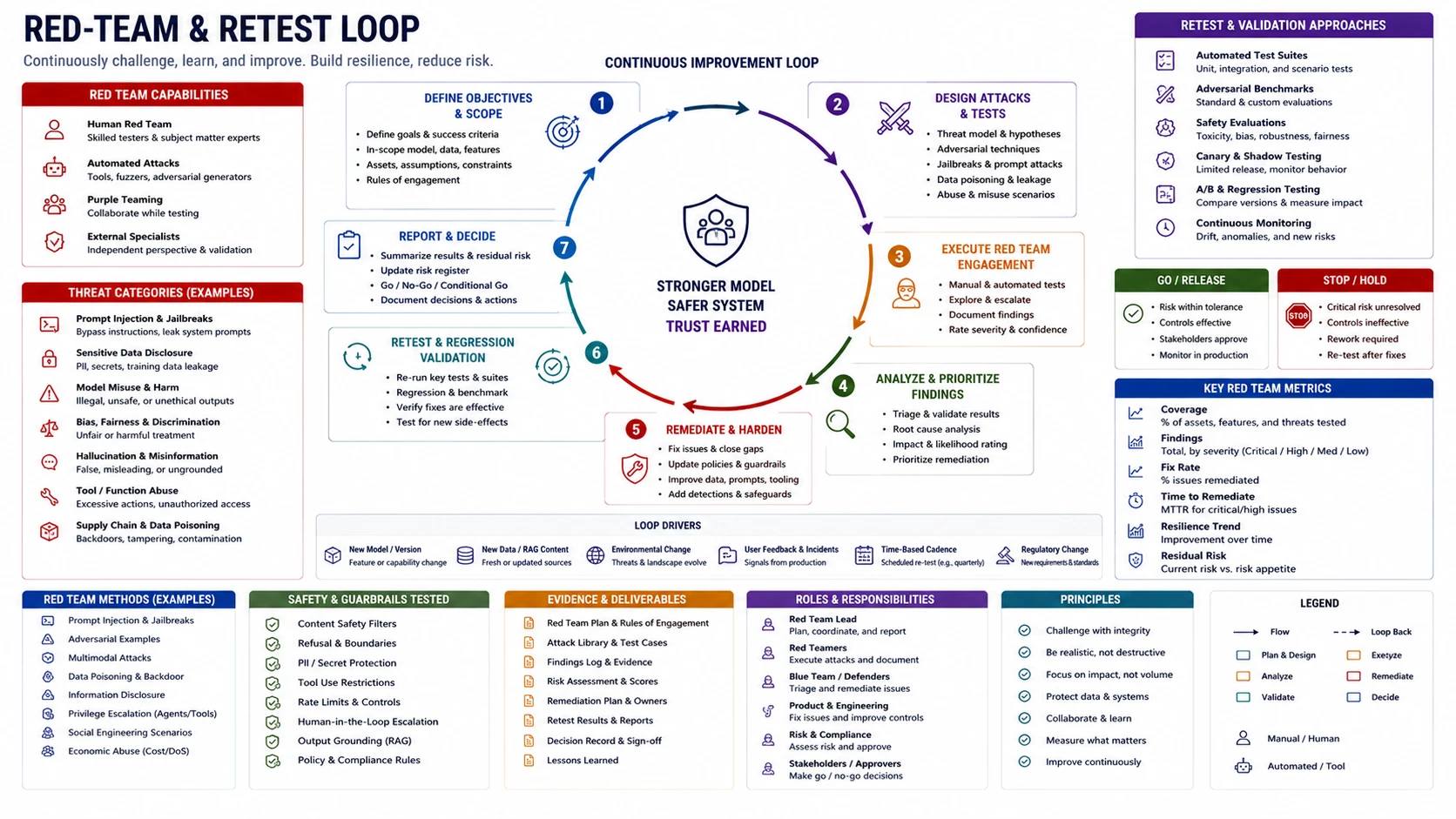
When to use: Before production launch of any high-risk system, tabletop exercises, post-incident, when adding tools or retrieval sources that expand the incident surface.
MAP
MAP
ATTACK
ATTACK — Tabletop scenarios
- Prompt injection with side effect: scope affected users, data accessed, state changed.
- Cross-tenant retrieval: scope chunks served, users affected, exposure window.
- Compromised provider: scope the exposure window and customer communication need.
- Poisoned artifact: scope when the mismatch was introduced and the rollback path.
- Runaway tool loop: scope what executed and the reversal path.
- Missing logs: triage maximum possible scope without the missing evidence.
DEFEND
DEFEND — Required controls
- Named system owner, provider contact, and escalation path verified before launch.
- Tested containment procedures: tool disable, token revoke, index freeze, model/prompt rollback, feature disable — each with a named authorized person.
- Evidence preservation procedure to a tamper-resistant location at incident declaration.
- Runbooks for prompt injection, cross-tenant retrieval, compromised artifact, runaway loop, data exposure, provider outage.
- Recovery verification: no recovery declared until contained scope and remediation are demonstrated.
- Tabletop exercises at least annually and after significant incidents.
- Customer-safe incident summary template distinct from the internal record.
Stop-ship conditions
- No containment path exists for tool disablement, token revocation, or rollback.
- No emergency revocation procedure exists or has been tested.
- Context, retrieval, and tool-call evidence cannot be preserved without manual procedures.
- No named provider incident contact for a provider handling sensitive data.
Escalate when
EVIDENCE
EVIDENCE
- Design: owner and escalation path, containment action catalog, runbooks.
- Implementation: evidence preservation procedure, rollback documentation.
- Validation: tabletop records, containment drill results.
- Runtime: incident records with timeline and containment actions taken.
Minimum evidence package
Containment action catalog, runbooks for high-priority incident types, provider contact records, a tabletop record from the last 12 months. Block approval if any containment action is untested.
Field decision questions
- Can the team scope a cross-tenant incident using only existing logs?
- Who has authority to execute each containment action?
- What is the maximum time from declaration to first containment action?
- How does an incident finding become a regression test case?
Outputs
- Incident response playbook.
- Containment action catalog.
- Tabletop exercise results.
- Post-incident control update record.
Related domains
| Domain | When to consult |
|---|---|
| [Logging and Telemetry](/handbook/2026#chapter-10) | Investigation evidence depends entirely on telemetry coverage. |
| [Detection Engineering](/handbook/2026#chapter-11) | Detection is the handoff point into incident response. |
| [Evaluation and Regression Testing](/handbook/2026#chapter-13) | Post-incident findings become regression test cases. |
AI SECURITY ENGINEERING FIELD GUIDE · 13
Evaluation and Regression Testing
Inspect
AI features, model providers, connectors, training-use terms, retention, support access, and change controls.
Produce
Vendor intake, connector review, contract notes, questionnaire evidence, and procurement recommendation.
“One successful sample does not prove a control. Proof requires deterministic assertions across change-triggered suites.”
Evaluation review
Verify each release is gated by a test suite covering critical behaviors, abuse cases, and threat model scenarios — running on every change to model, prompt, retrieval, or tools.
Security evaluation differs from quality evaluation: it checks whether controls hold under adversarial conditions, not whether outputs are useful. Red teaming is one method of generating test cases — it is not the complete definition of this domain. The output of a red-team engagement is test cases that belong in the regression suite. The suite is what blocks releases.
Write release-gate criteria before writing tests. One passing run does not meet the bar — sample size, variance, and adversarial coverage must be specified in advance.
When to use: Before every production release; on model, prompt, retrieval, or tool-scope change; after incidents.
MAP
MAP
ATTACK
ATTACK
- Adversarial prompts derived from threat model abuse paths.
- Indirect injection through the full retrieval and tool path, not isolated calls.
- Unauthorized and cross-tenant retrieval against the live authorization path.
- Excessive agency: chained permitted steps toward an unauthorized outcome.
- Repeated sampling across the output distribution, not a single run.
- Degraded dependencies: retrieval failure, tool error, provider timeout.
DEFEND
DEFEND — Required baseline
- Product-specific security test suite reflecting actual abuse paths, not generic benchmarks.
- Deterministic assertions: authorization checks, schema validation, logged-event presence.
- Change-triggered execution on every model, prompt, retrieval, or tool-scope change.
- Release blocking on security-critical test failure, threshold defined in advance.
- Regression promotion of incident and red-team findings within a defined window.
DEFEND — Cross-cutting lenses and high-risk
- Red Team lens: scope engagements from threat model abuse paths; convert validated findings to deterministic test cases; verify fixes via the regression suite.
- Secure SDLC lens: failing tests accepted as risk exceptions require owner, expiry, compensating control, retest plan. Eval gates are required in artifact promotion, not optional.
- High-risk systems
- Probabilistic thresholds with documented sample sizes and conservative cutoffs.
- LLM-based evaluators calibrated for the specific assertion type before use as a gate.
- Advanced maturity
- Continuous evaluation sampling production traffic against security assertions.
Stop-ship conditions
- No product-specific security tests exist, only generic benchmarks.
- One successful sample is presented as proof a control holds.
- A failing security test does not block release.
- Incident or red-team findings are not converted into regression tests.
Escalate when
EVIDENCE
EVIDENCE
- Design: release gate definitions, abuse-case-to-test mapping.
- Implementation: test suite composition, change-trigger configuration.
- Validation: suite execution results per release, regression results.
- Governance: exception register, coverage gap register.
Minimum evidence package
Release gate definitions, current-release test execution results, regression results covering recent incidents, exception register. Block approval if any security-critical test fails without an accepted exception.
Field decision questions
- Which abuse paths lack a corresponding test case?
- What is the release-blocking threshold for each security assertion?
- When was the suite last updated after a real incident?
- Who owns the exception for a failing test, and when does it expire?
Outputs
- Security test suite with release gates.
- Test execution results per release.
- Regression coverage map.
- Exception register.
Related domains
| Domain | When to consult |
|---|---|
| [Threat Modeling](/handbook/2026#chapter-03) | Abuse paths are the primary input for test suite scope. |
| [RAG Authorization](/handbook/2026#chapter-05) | Cross-tenant and stale-ACL cases belong in the regression suite. |
| [Incident Response](/handbook/2026#chapter-12) | Post-incident findings convert into regression tests here. |
AI SECURITY ENGINEERING FIELD GUIDE · 14
Governance Evidence and Customer Trust
Design
Secure AI architecture
Put enforcement where the model can be wrong and the system still stays safe.
“Every external claim is a traceability obligation. Trace it to a control, an owner, a test, and a current artifact.”
Governance evidence review
Verify every external AI security claim traces to a named control, a current artifact, an owner, and a test result — and no claim exceeds what the evidence supports.
A trust-center statement or questionnaire answer is not a control — it is a claim that must survive an evidence request. This domain is the aggregator: it does not produce controls. It verifies the other 13 domains have produced the evidence backing any governance or customer-facing statement.
Start with one external claim. Trace it: claim → control → owner → test result → current artifact. If any link is missing, the claim cannot be published. Work in that direction, not from controls to claims, or you will miss what was promised but never built.
When to use: Customer questionnaires, trust-center publication, third-party audits, governance reviews, customer assurance requests.
MAP
MAP
ATTACK
ATTACK
- Pick one published claim and trace it fully; flag any missing link.
- Compare artifact dates against the defined freshness window.
- Sample five controls; verify each has a reachable owner who can produce evidence on demand.
- Review open exceptions for expiry past due.
- Trace a contract commitment to its control, implementation, and test result.
- Compare answers across the last three questionnaires for consistency.
- Attempt to reproduce a governance artifact without advance notice.
DEFEND
DEFEND — Required baseline
- Control registry: identifier, objective, owner, evidence location, test cadence, failure response.
- Named owner per evidence artifact responsible for accuracy and freshness.
- Claim approval step confirming traceability to a current control and artifact before publication.
- Defined freshness windows; claims re-confirmed when artifacts exceed them.
- Exception expiry dates with review triggered before renewal or closure.
- Remediation tracking for stale evidence and unsupported claims as backlog items.
DEFEND — Cross-cutting lenses and high-risk
- Procurement lens: verify live provider configuration against committed terms before answering any questionnaire referencing provider behavior.
- Customer assurance: a defined customer-safe evidence package — audit summaries, test summaries — without exposing internal architecture or raw logs. Claims classified as fully supported, supported with caveat, or not claimable.
- High-risk systems
- Framework crosswalk mapping each requirement to a named control and current artifact.
- Compensating controls documented and reflected in claims with caveats where objectives are partially met.
- Advanced maturity
- Continuous evidence monitoring dashboard tracking freshness and claim-readiness in real time.
Stop-ship conditions
- A published claim has no traceable supporting control or evidence artifact.
- Governance evidence is stale beyond its freshness window.
- An open exception has no owner or has passed expiry.
- A high-risk control failure is not reflected in assurance materials.
Escalate when
EVIDENCE
EVIDENCE
- Design: control registry, claim-readiness classification, framework crosswalk.
- Implementation: control configurations traceable to objectives, exception records.
- Validation: claim-to-artifact trace results, questionnaire consistency checks.
- Governance: freshness review records, remediation backlog.
Minimum evidence package
Control registry, claim-readiness classification per external claim, evidence freshness review, exception register. Do not publish a claim that fails the control trace.
Field decision questions
- Which published claims cannot be fully traced to a current control and artifact?
- Which artifacts have exceeded their freshness window?
- Who owns each open exception, and when does it expire?
- Does the live provider configuration match what customer commitments describe?
Outputs
- Control registry.
- Claim-readiness register.
- Framework crosswalk.
- Governance remediation backlog.
Related domains
| Domain | When to consult |
|---|---|
| [AI System Inventory](/handbook/2026#chapter-01) | Source of record for every system-level governance claim. |
| [Data Exposure and Privacy](/handbook/2026#chapter-07) | Provider data-use terms are primary governance claims. |
| [Evaluation and Regression Testing](/handbook/2026#chapter-13) | Test and exception records are primary validation evidence. |