
How to Read the State of AI Security Engineering Report: Methodology, Caveats, and Responsible Interpretation
A serious annual report is not only a collection of findings. It is also a contract with the reader about how those findings should be interpreted. The more ambitious the report, the more important the methodology becomes.
Private Benchmarks for AI Security: Skills, Operating Models, Controls, and Governance Evidence
Private AI security benchmarks can help organizations compare skills, operating models, control coverage, evidence maturity, and role expectations against defined datasets or frameworks, but they must be presented as directional advisory tools rather than certification, audit opinion, or proof of internal security maturity.
Claim-Readiness for AI Security: Marketing Pages, Trust Centers, Sales Claims, and Governance Evidence
Claim-readiness means AI security, privacy, governance, benchmark, sponsorship, and trust-center claims are mapped to reviewable evidence, scoped carefully, caveated honestly, and separated from unsupported product endorsement or research overstatement.
Psychometric Role-Language Evidence Is Not Diagnosis: Responsible Use in AI Security Workforce Research
Psychometric role-language analysis can help interpret AI security job descriptions, role expectations, team archetypes, and skills demand when used as aggregate evidence with clear limitations. It must not be used to diagnose individuals, infer protected traits, make unsupported hiring decisions, or imply internal company maturity.
Public Hiring Signals: How AI Security Job Descriptions Reveal Market Demand Without Proving Internal Maturity
Public AI security job descriptions can reveal directional market demand, role architecture, skills convergence, framework adoption, and emerging operating models, but they cannot prove internal security maturity. Job-description intelligence should be analyzed in aggregate, caveated carefully, and separated from company-level accusations.
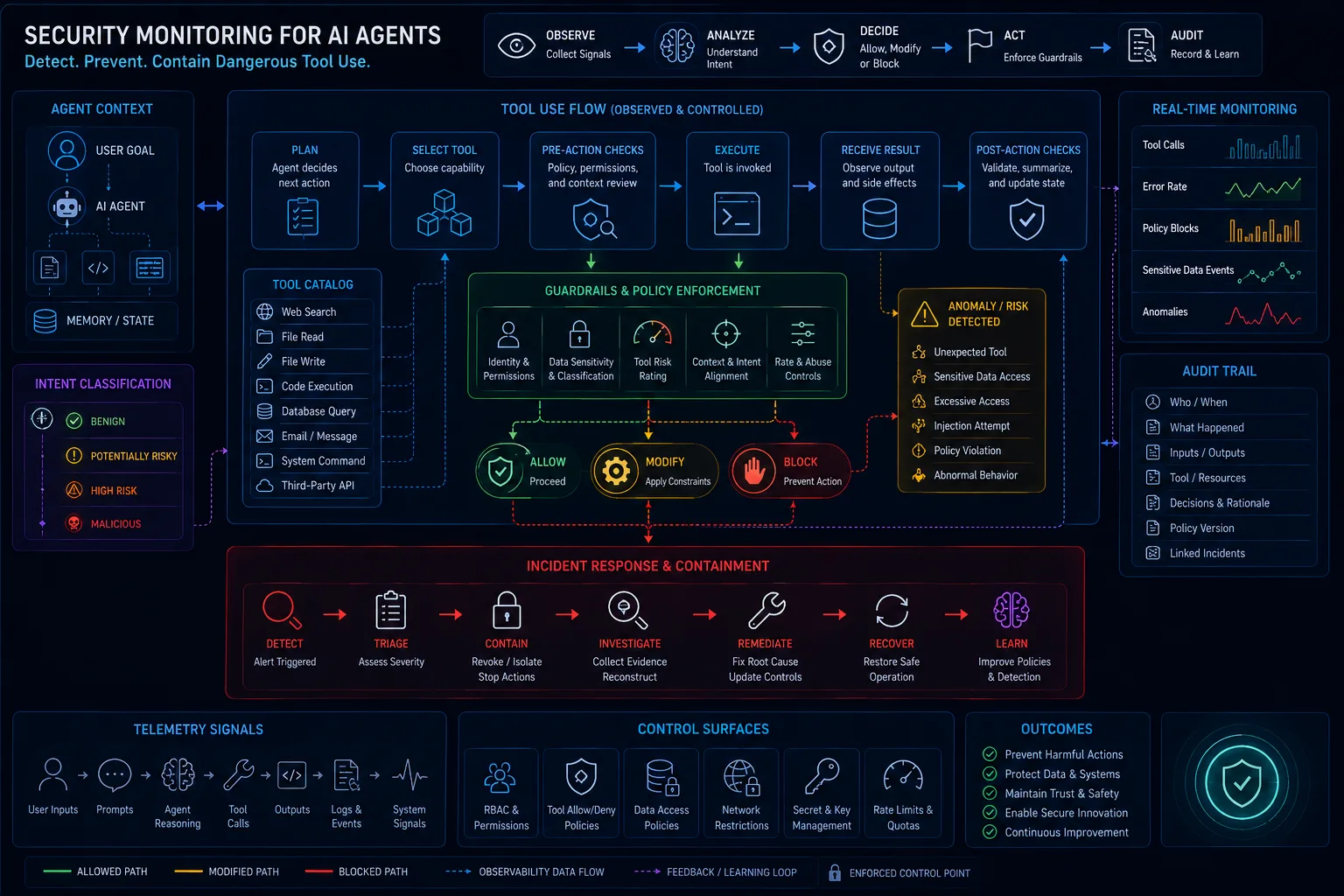
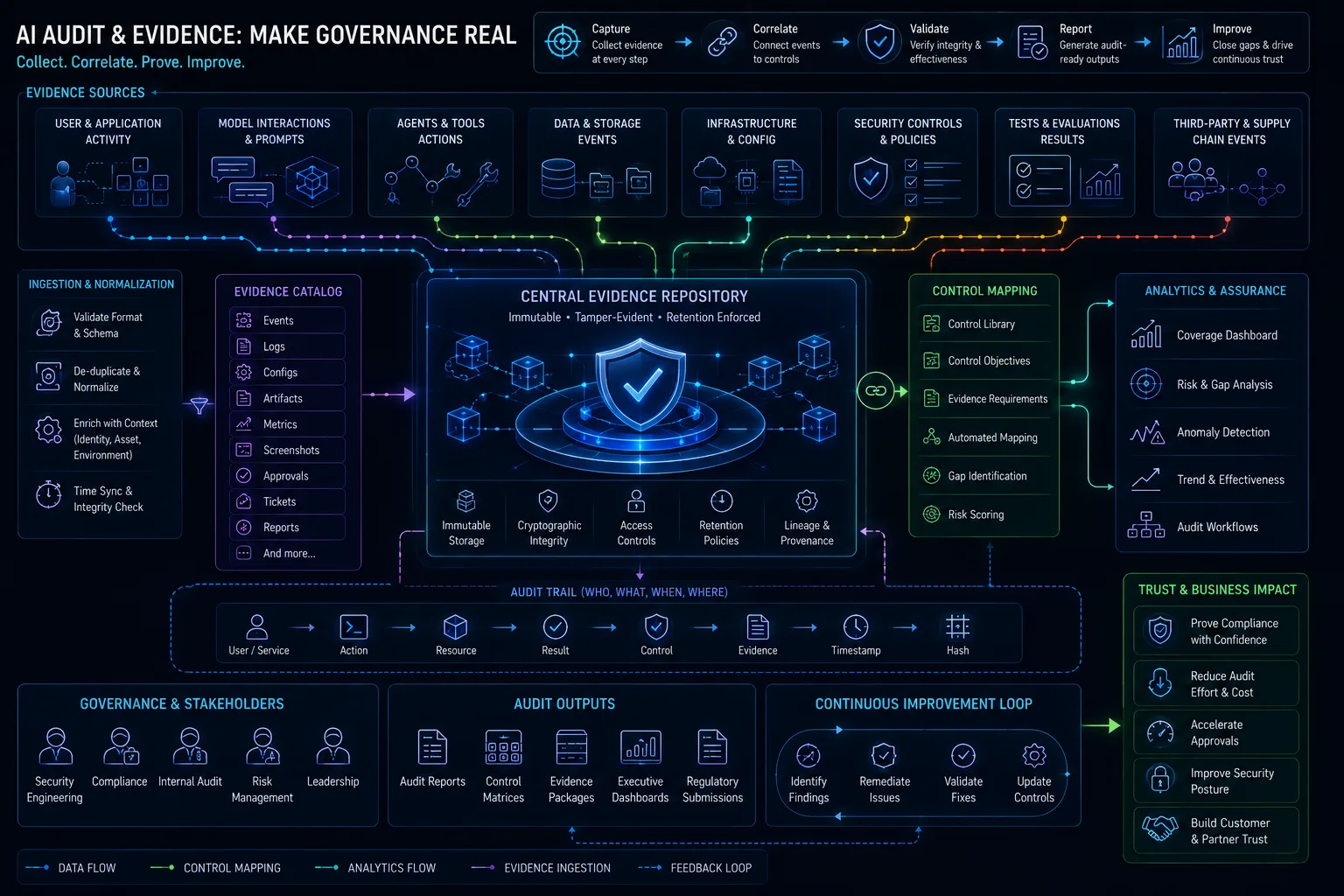
AI Audit Evidence: What Logs, Tests, Policies, and Approvals You Need to Prove Governance Works
AI governance requires evidence artifacts across inventory, risk, data, providers, prompts, evals, red-teaming, approvals, and logs. Evidence should be built into AI workflows, not assembled after a crisis.
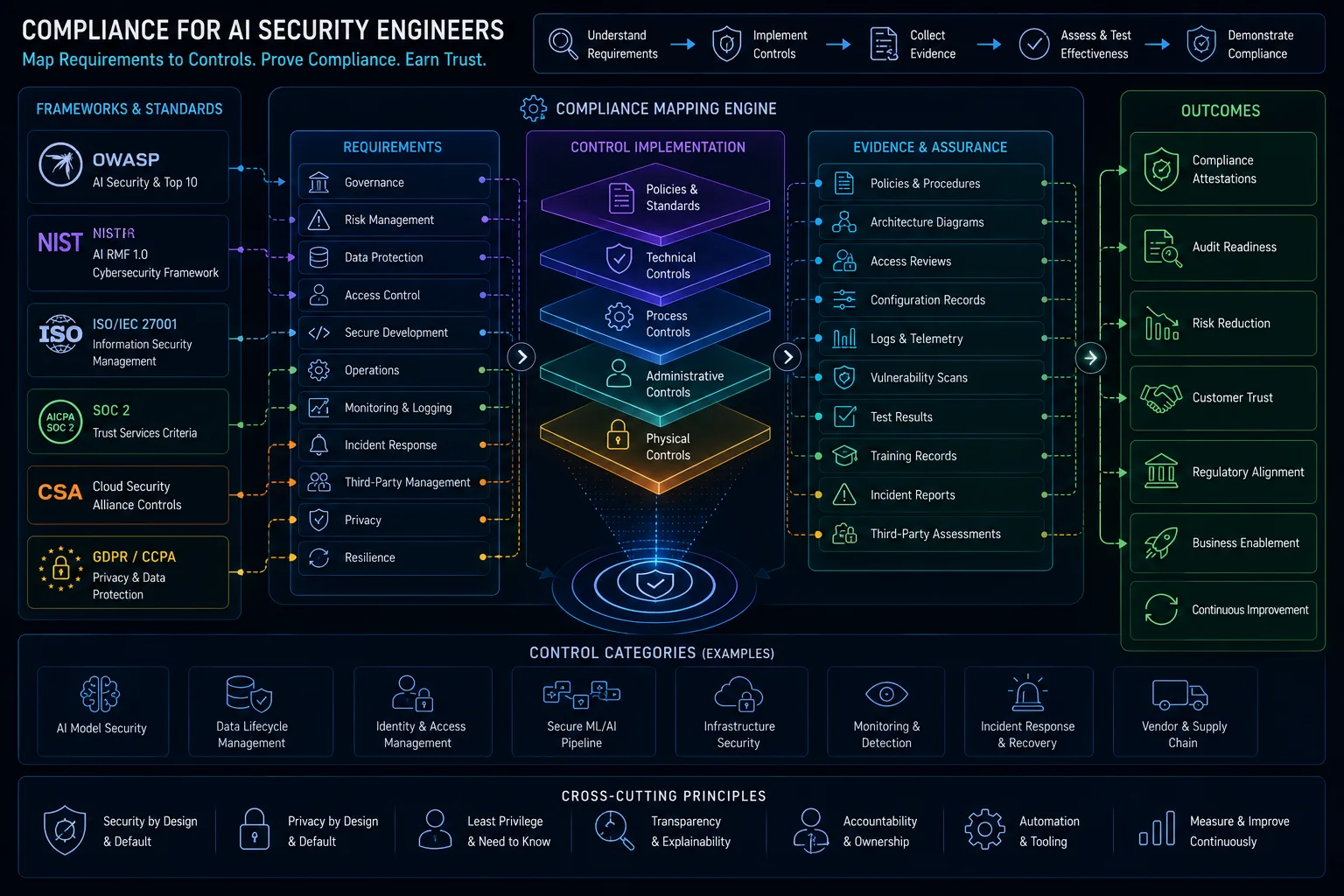
Compliance for AI Security Engineers: Mapping OWASP, NIST AI RMF, ISO 42001, SOC 2, and CSA AICM
AI security compliance should translate frameworks into concrete engineering controls and governance evidence. OWASP helps with LLM application risks, NIST AI RMF with risk management, ISO 42001 with management-system structure, SOC 2 with trust-service evidence, and CSA AICM with control mapping, but none of these prove an AI system is secure on their own.
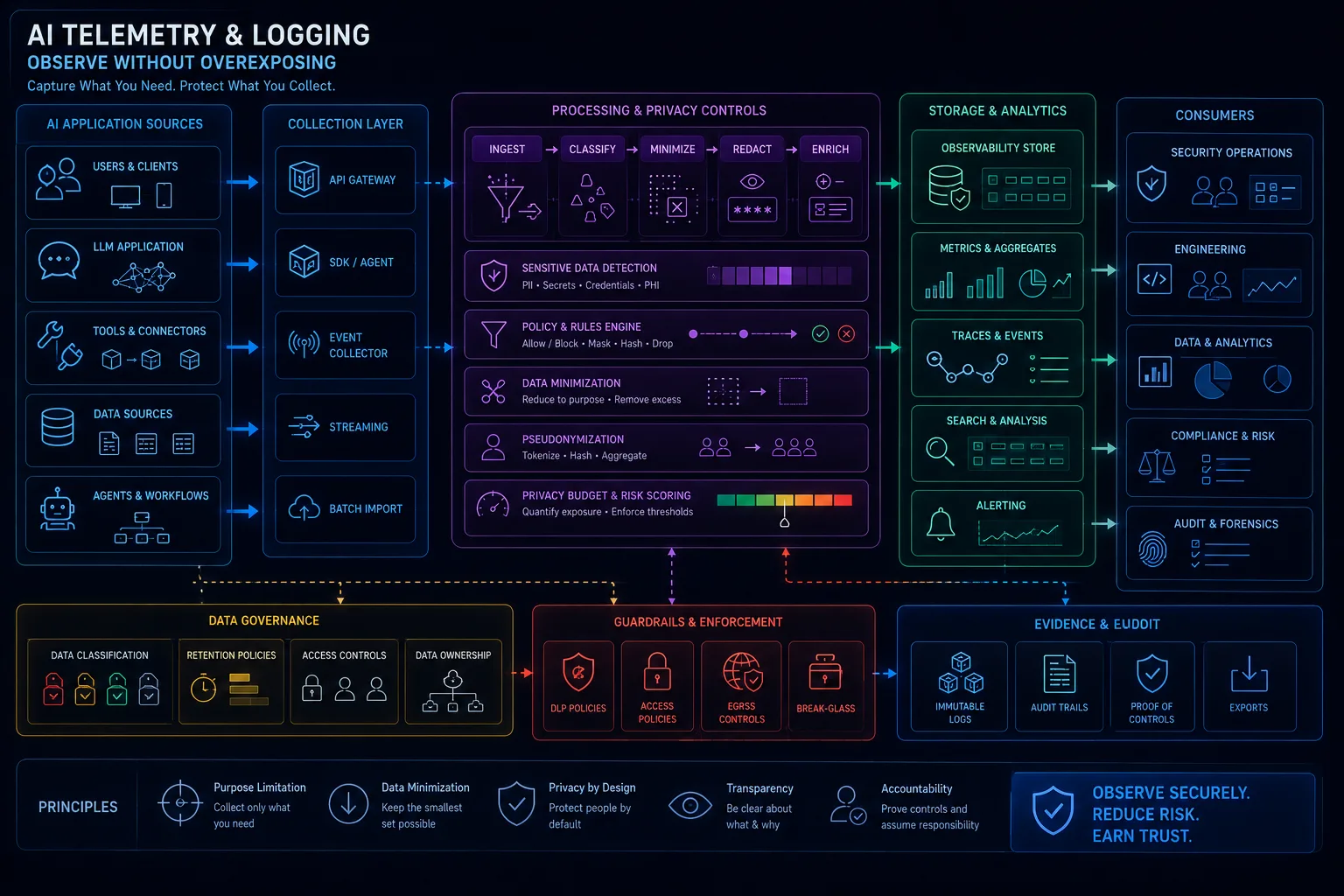
AI Data Governance for Security Engineers: Classifying Prompts, Outputs, Embeddings, and Training Data
AI data governance must classify prompts, outputs, embeddings, and training data. Security engineers need rules for provider use, retention, access, and deletion.

Human-in-the-Loop Is Not a Security Control Unless You Design It Like One
Human-in-the-loop is only a security control when the approval is timely, informed, auditable, placed before meaningful action, and backed by authority to deny or modify the action. Otherwise it becomes a weak UX pattern that shifts responsibility to users without giving them enough information to exercise judgment.