Evaluation and Regression Testing
10 articles
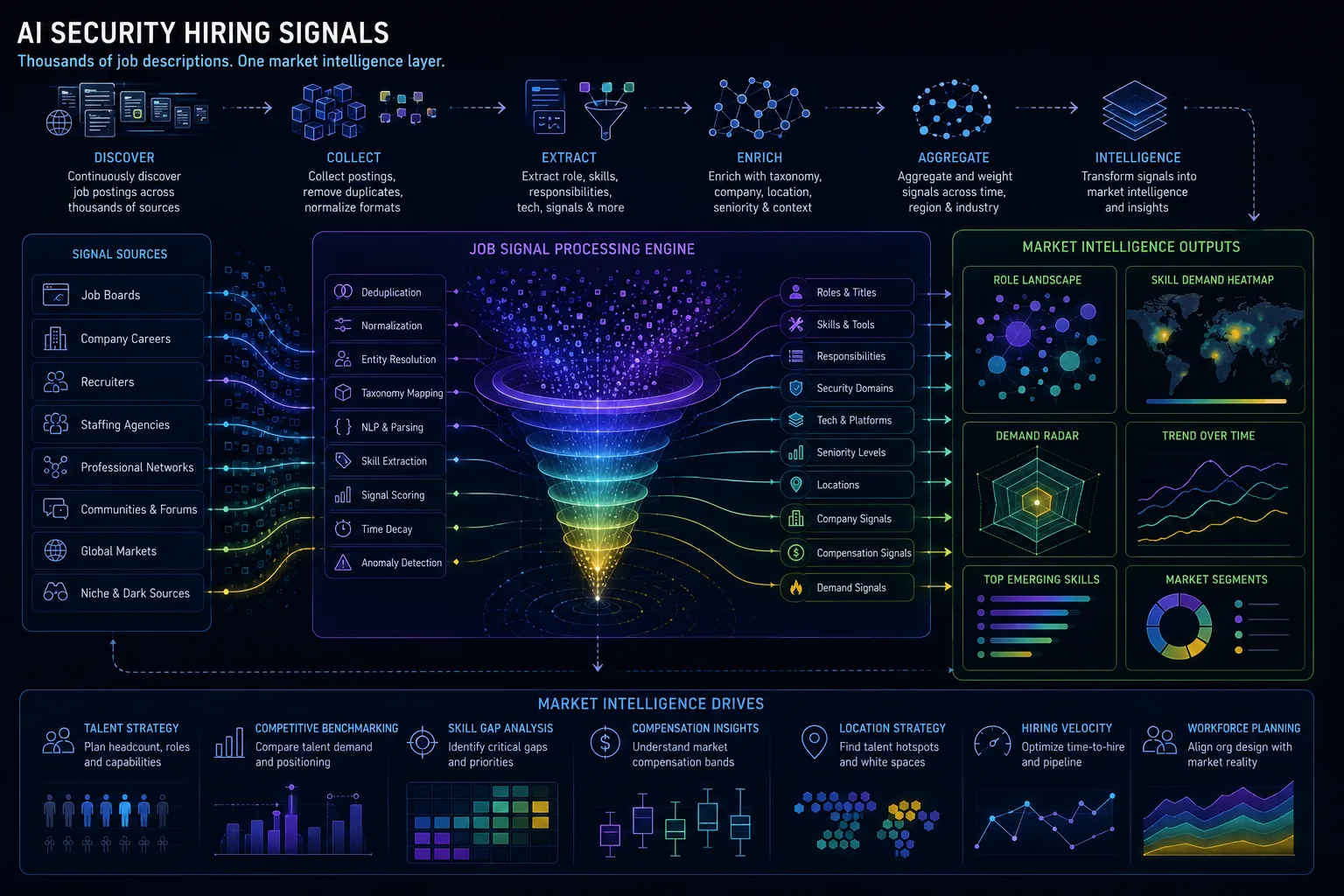
The AI Security Engineer Career Map: Skills, Tools, Frameworks, and Portfolio Evidence
The AI Security Engineer career path combines AppSec, cloud security, MLOps, LLM application security, secure RAG, agent security, red teaming, detection engineering, governance evidence, privacy awareness, and communication. Practitioners should build portfolio evidence that proves they can turn AI risk into controls, tests, telemetry, and operating decisions.
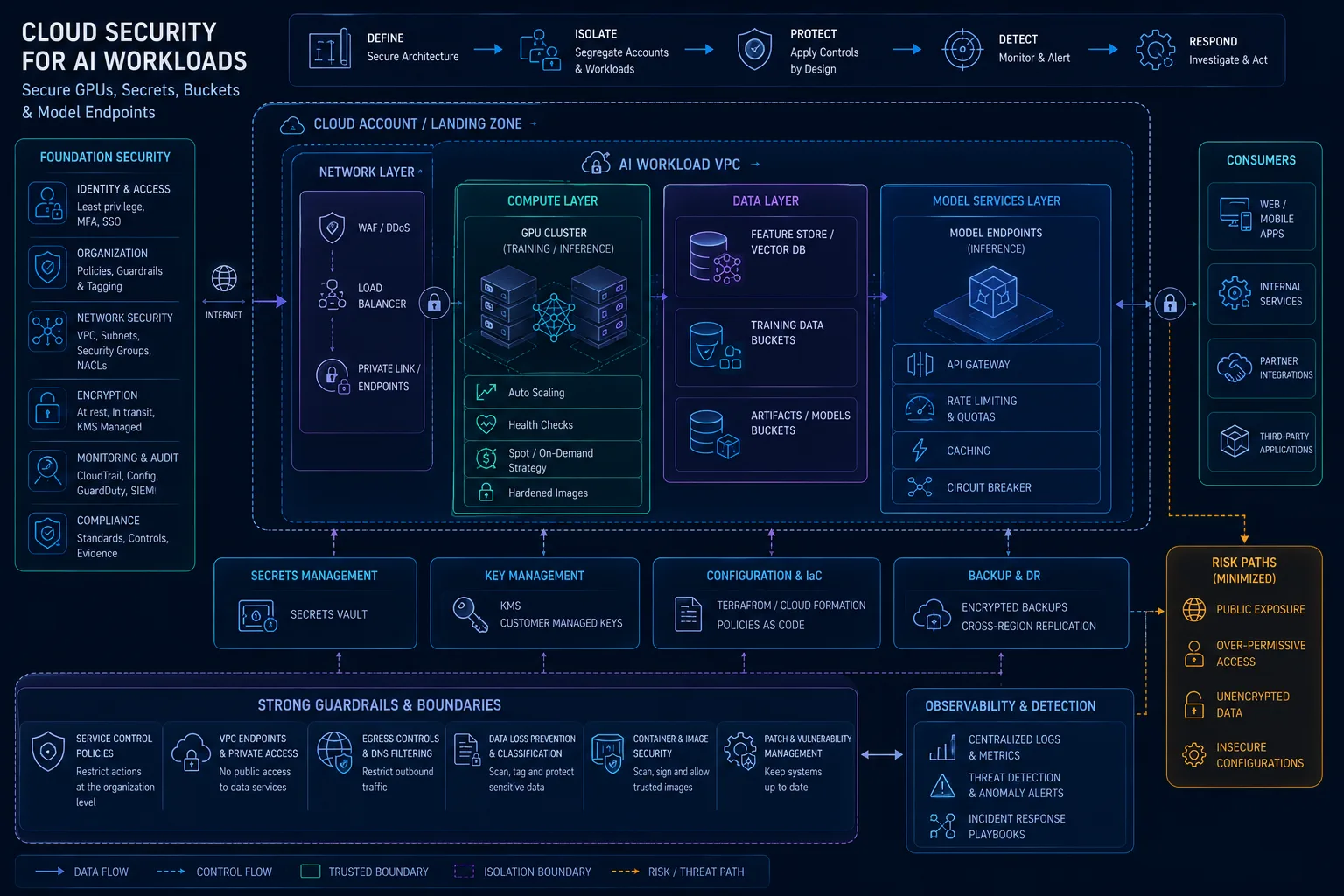
The AI Security Buyer’s Guide: How to Evaluate Vendors for LLM Firewalls, Guardrails, Evals, and Monitoring
AI security buyers should judge vendors by the job to be done: filtering, testing, evals, access, logs, leaks, rules, and proof. Choosing a vendor should start with design and risk, not just labels.
AI Audit Evidence: What Logs, Tests, Policies, and Approvals You Need to Prove Governance Works
AI governance requires evidence artifacts across inventory, risk, data, providers, prompts, evals, red-teaming, approvals, and logs. Evidence should be built into AI workflows, not assembled after a crisis.
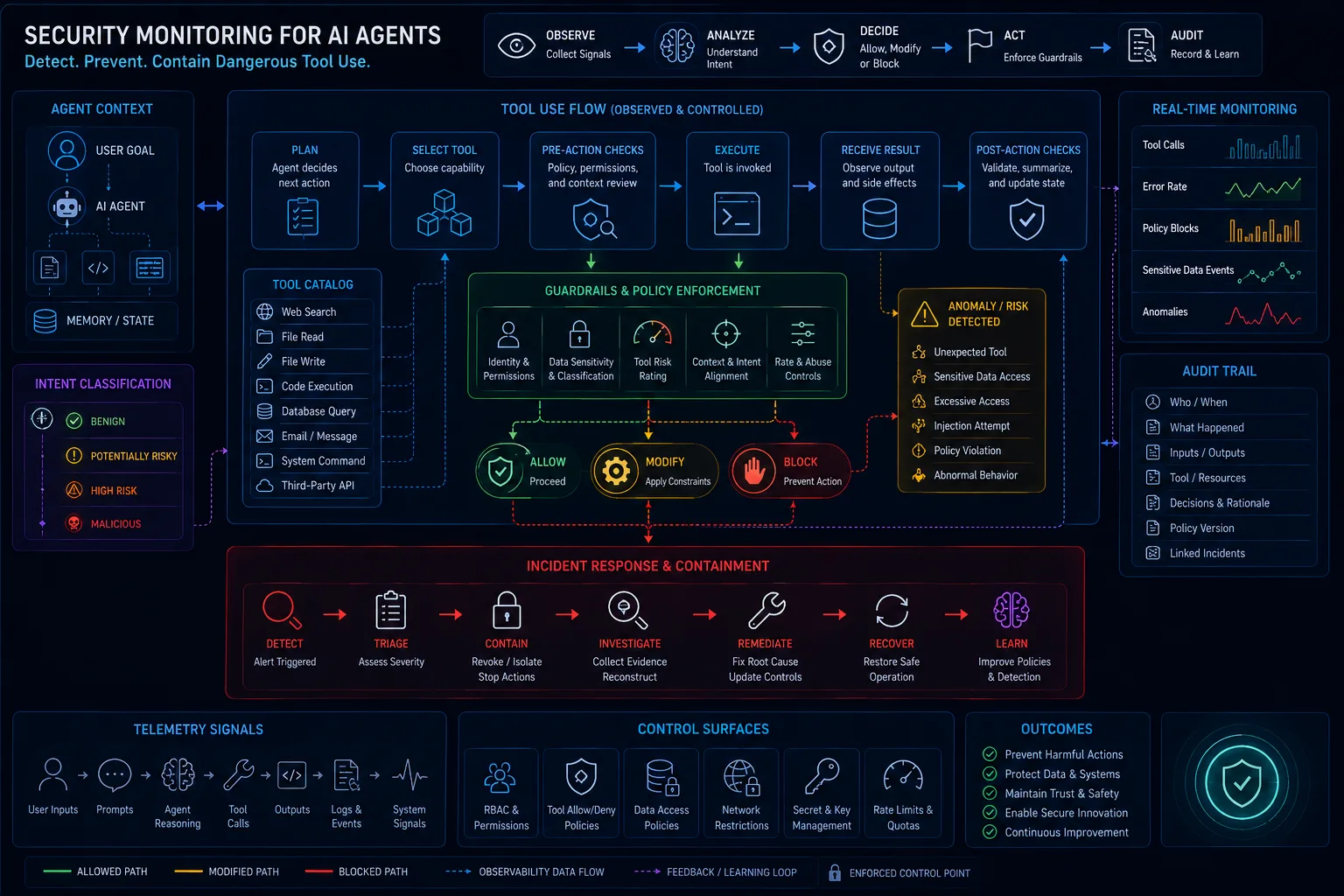
AI Application Security Review Checklist: 100 Questions Before Production Launch
AI security reviews should use a structured checklist covering governance, data, prompts, RAG, tools, agents, providers, evals, telemetry, and claims before launch.
From Jailbreaks to Business Impact: How to Write AI Security Findings That Executives Understand
AI security findings should connect tested behavior to business impact through scope, preconditions, evidence, reproducibility, affected assets, control failure, severity rationale, and remediation. Findings must avoid unsupported company-level claims, product endorsement language, and exaggerated conclusions.
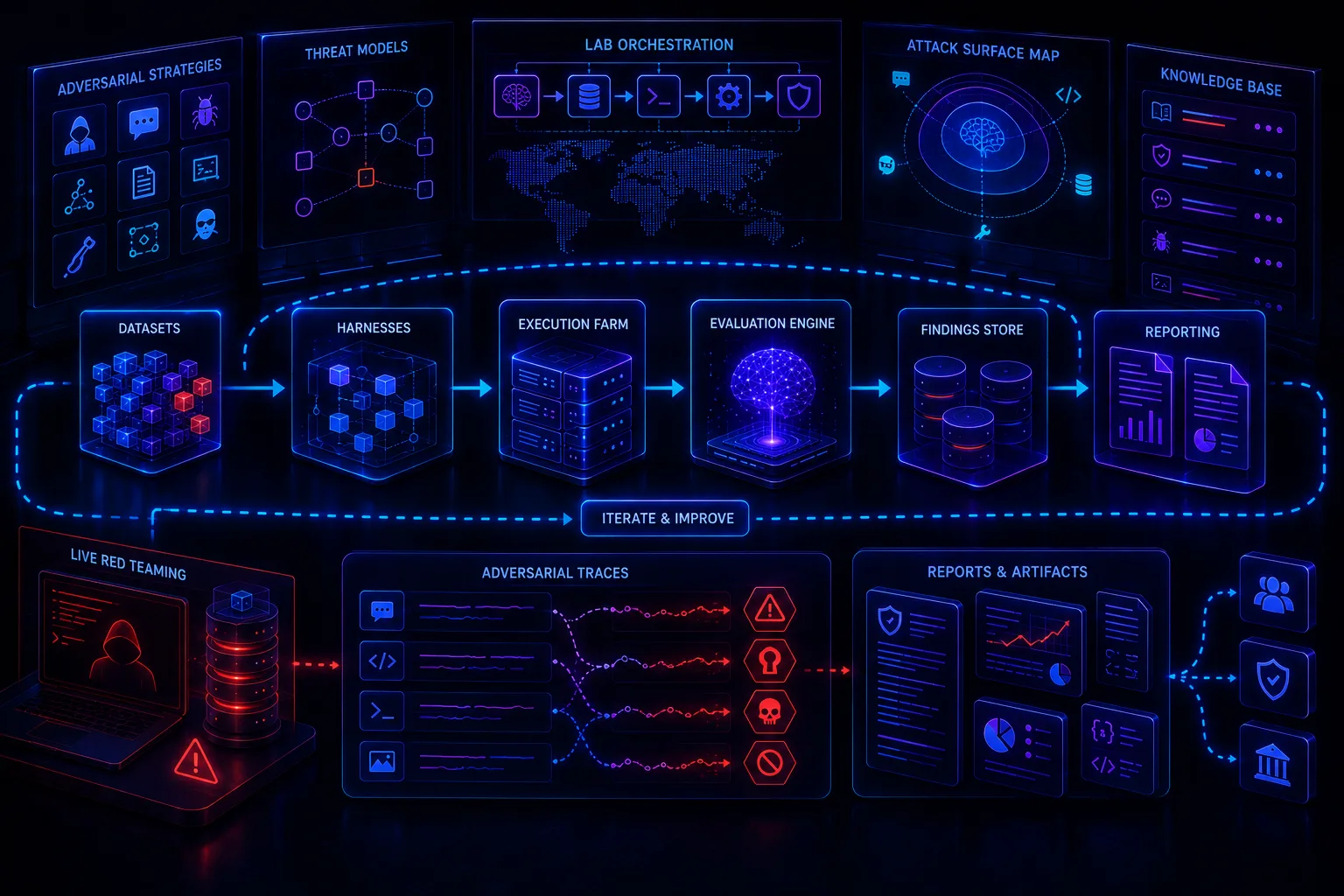
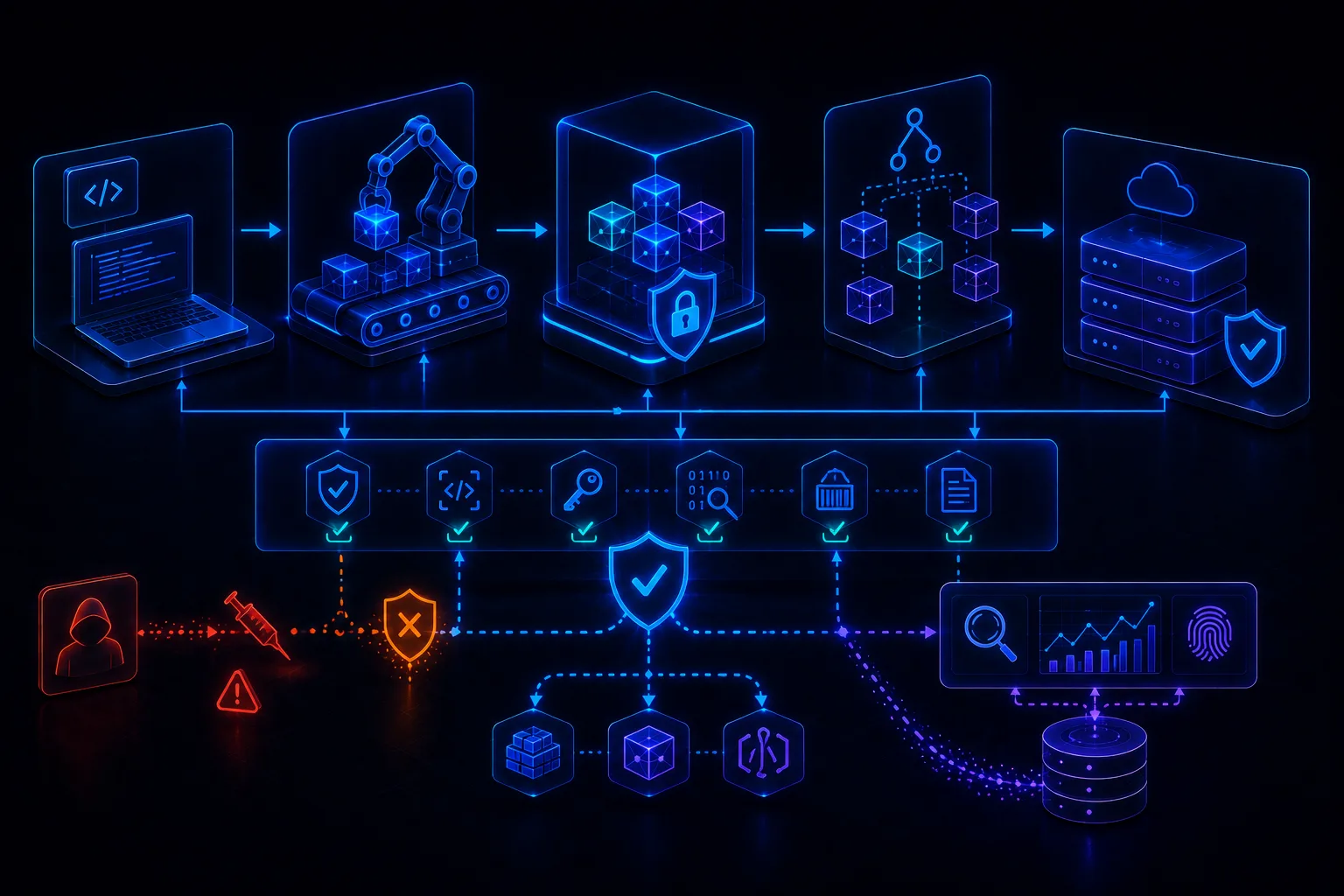
Building an AI Red Team Lab: Tools, Datasets, Harnesses, Attack Libraries, and Reporting Templates
An AI red team lab should provide a controlled, authorized, reproducible environment for testing LLM applications, RAG systems, AI agents, model endpoints, tool use, output handling, and governance evidence. It must include safe datasets, attack libraries, test harnesses, telemetry, evidence handling, reporting templates, and operational guardrails.

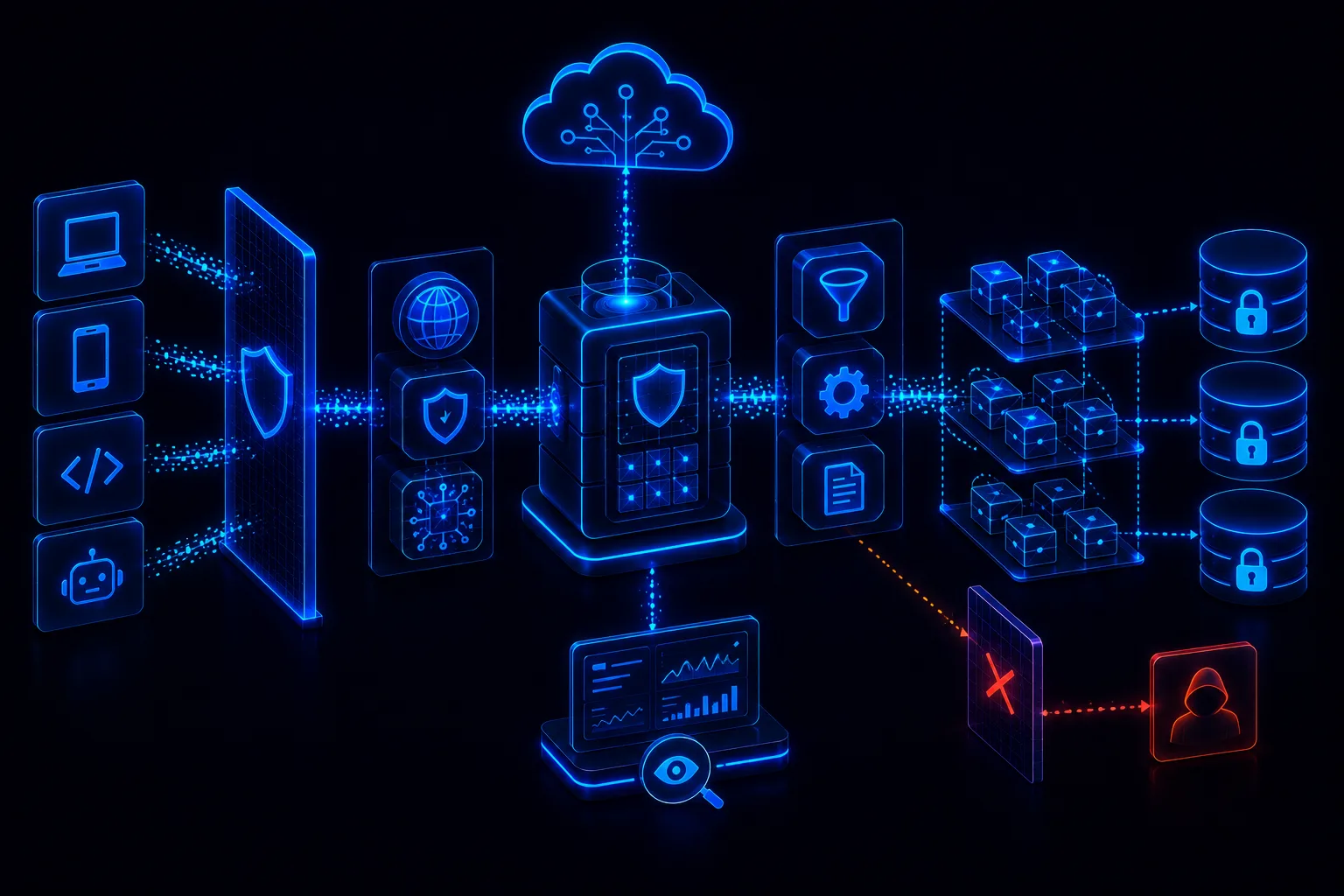
AI Evals as Security Tests: Building Regression Suites for Prompt Injection, Leakage, and Unsafe Actions
Security evals should test prompt injection, indirect injection, data leakage, RAG access, unsafe output, excessive agency, over-reliance, and cost abuse. These should be repeatable regression suites in CI/CD and governance evidence.
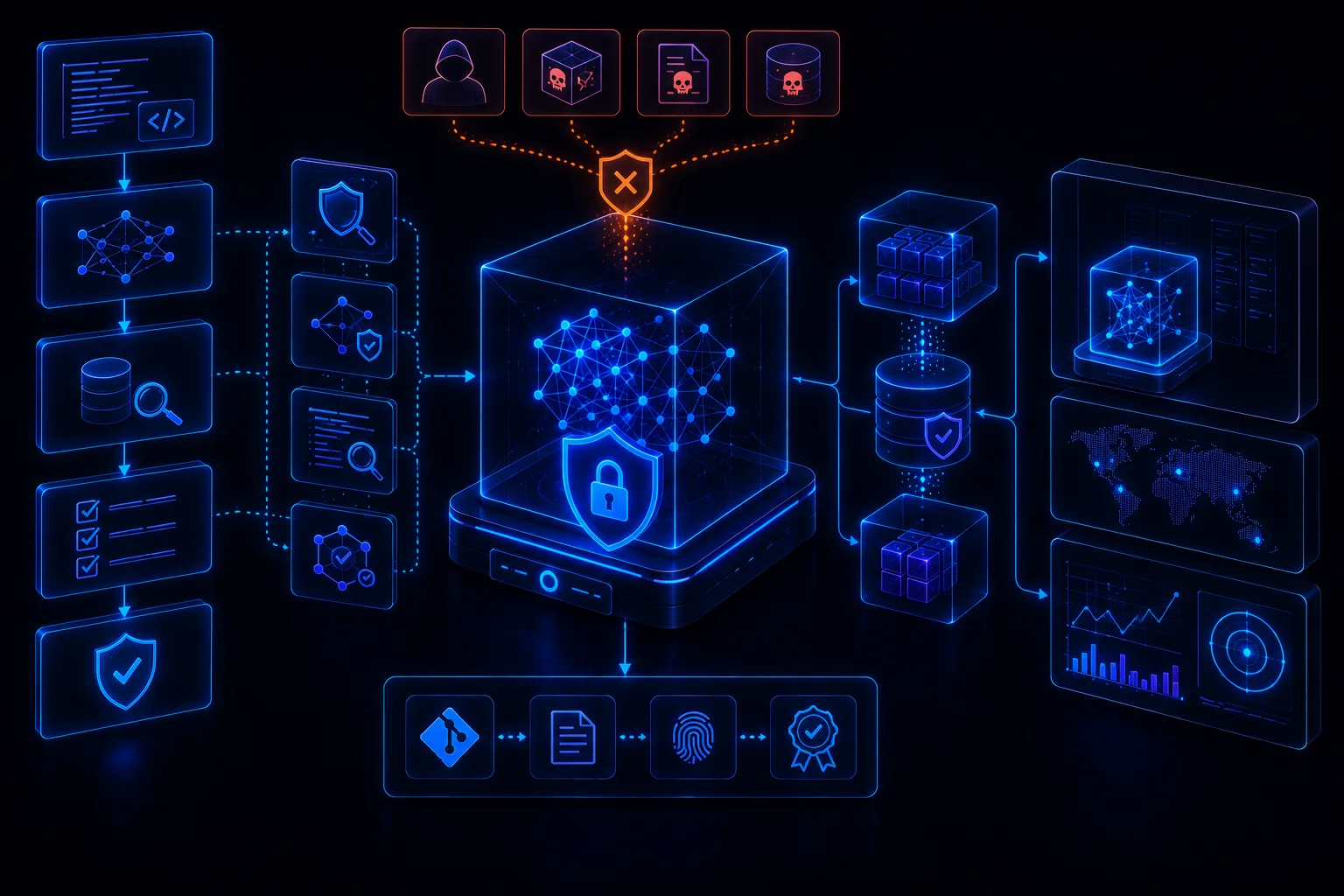
LLMOps Security: CI/CD, Secrets, Eval Gates, Model Registry Controls, and Deployment Promotion
LLMOps security requires CI/CD controls for prompts, tools, model configuration, provider routing, evals, secrets, registries, deployment promotion, monitoring, rollback, and governance evidence. AI release processes must track every artifact that can change system behavior.

AI Red Teaming 101: Scope, Methods, Evidence, and Deliverables for Real Organizations
The market often treats red teaming as a demonstration. Real organizations need more than that. They need authorization, reproducibility, severity judgment, and a retest plan that helps the engineering team move.

OWASP LLM Top 10 2025 Explained for Engineers Building Real AI Products
Teams adopt LLM features quickly and then discover that traditional AppSec checks miss retrieval abuse, tool misuse, and unsafe output handling. The Top 10 helps because it names the failure modes that need design and test work.