Prompt Injection
5 articles

AI Evals as Security Tests: Building Regression Suites for Prompt Injection, Leakage, and Unsafe Actions
Security evals should test prompt injection, indirect injection, data leakage, RAG access, unsafe output, excessive agency, over-reliance, and cost abuse. These should be repeatable regression suites in CI/CD and governance evidence.
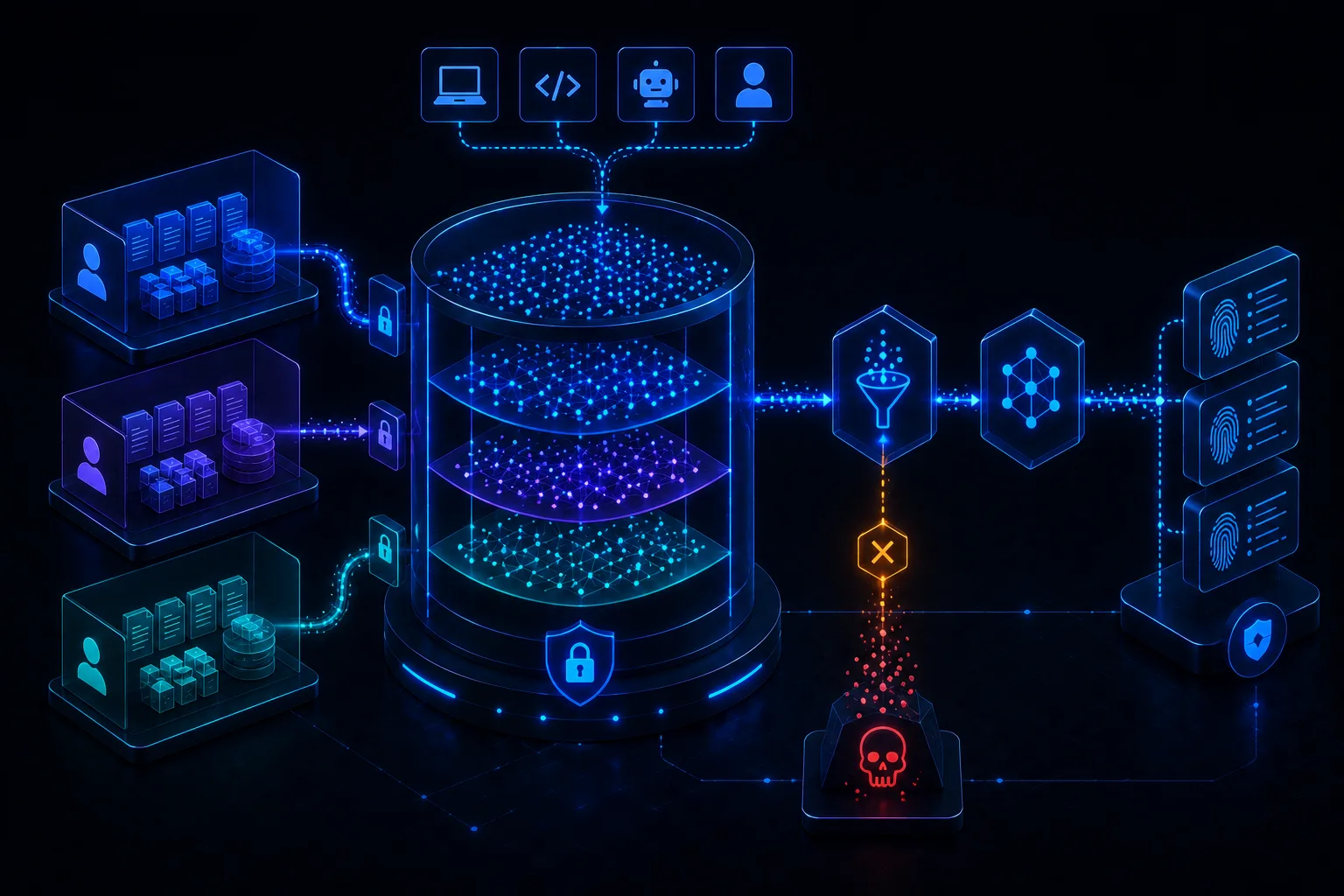
AI Data Governance for Security Engineers: Classifying Prompts, Outputs, Embeddings, and Training Data
AI data governance must classify prompts, outputs, embeddings, and training data. Security engineers need rules for provider use, retention, access, and deletion.

AI Incident Response: Playbooks for Prompt Injection, Model Abuse, Data Leakage, and Rogue Agents
Most incident teams already know how to isolate systems and preserve logs. AI changes the shape of the evidence. The response process must include prompts, retrieval context, tool actions, and model versions.

Prompt Injection Is Not a Prompt Problem
The mistake is to think better wording can defend a system that already gives the model too much reach. Once the model can read external content, call tools, and influence workflows, the real question becomes who controls the boundary.

OWASP LLM Top 10 2025 Explained for Engineers Building Real AI Products
Teams adopt LLM features quickly and then discover that traditional AppSec checks miss retrieval abuse, tool misuse, and unsafe output handling. The Top 10 helps because it names the failure modes that need design and test work.